I’m just documenting this quickly because it took me a comically long time to figure out where it was in the UI, the official documentation was hard to find, and I hope to save someone from the same goose chase.
If you need to create a ticket for Adobe Analytics or Adobe Experience Platform tools, you need to have the right permissions. We used to call these “Supported Users”; for a time they were “Customer Support Delegates”. It used to be tightly controlled- eg, an org could only have two supported users at any time, but these days it’s a bit more flexible.
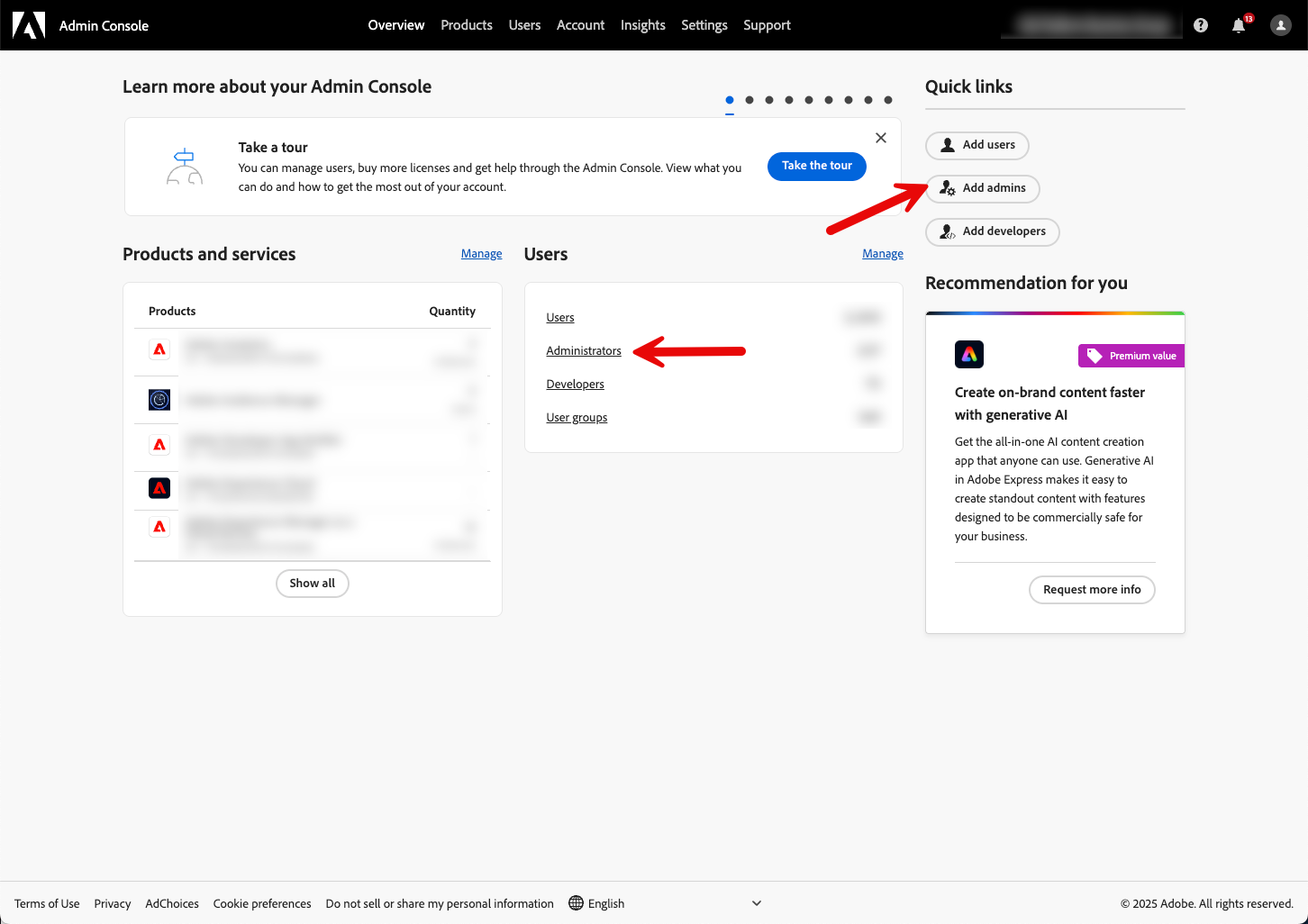
To give someone the right permissions, you must be a System Administrator yourself, and open the Admin Console. Then you need to start the “Add Admin” flow, either through the quick link in the upper right, or by looking at your list of Administrators:
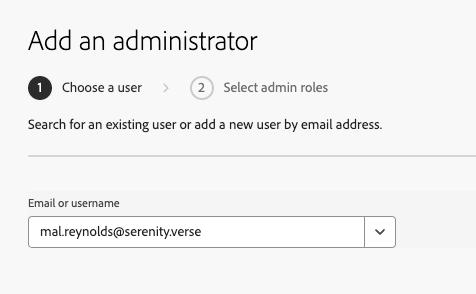
After you enter the user’s name and email:
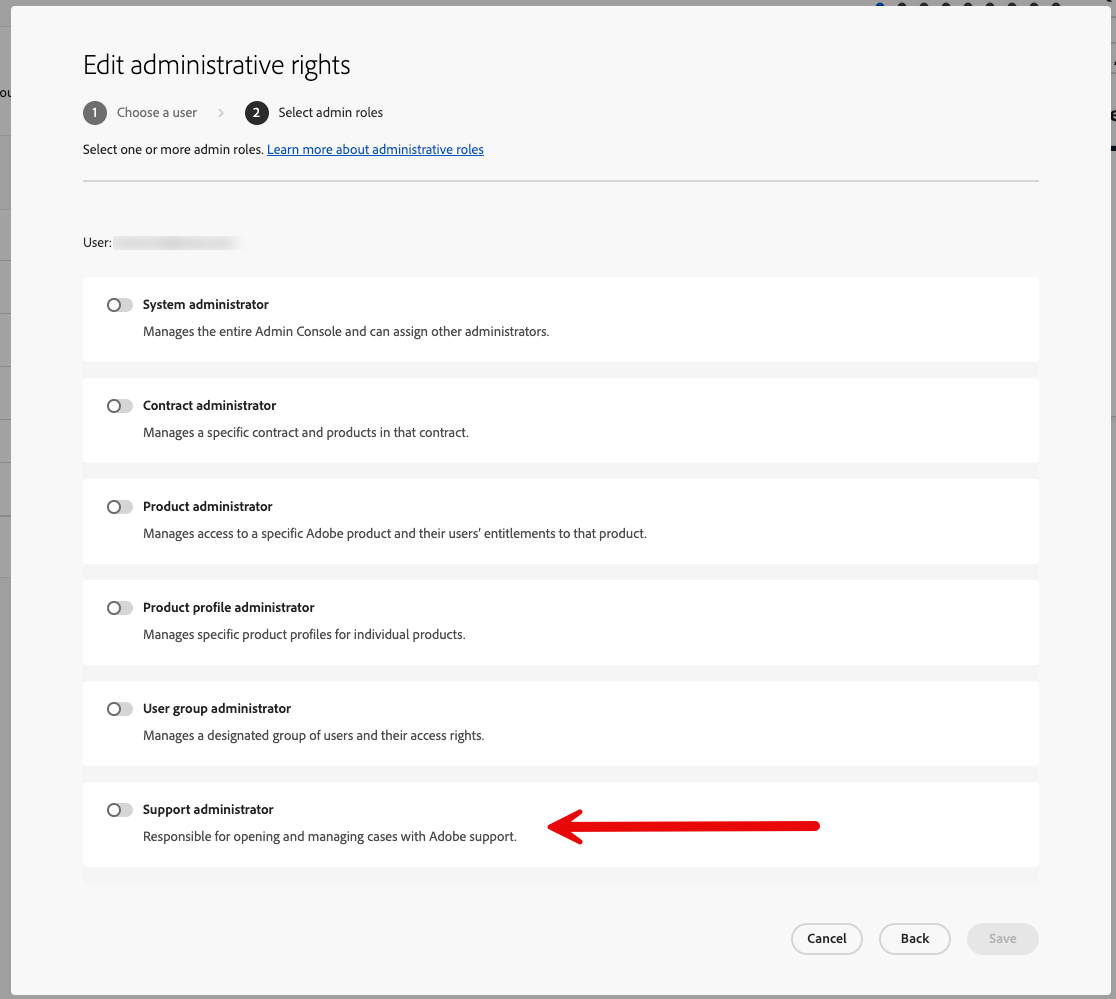
Click “next”, and toggle on “Support administrator”:
Hit save, and there you have it! The user should now be able to open the Support tab within the Admin Console:
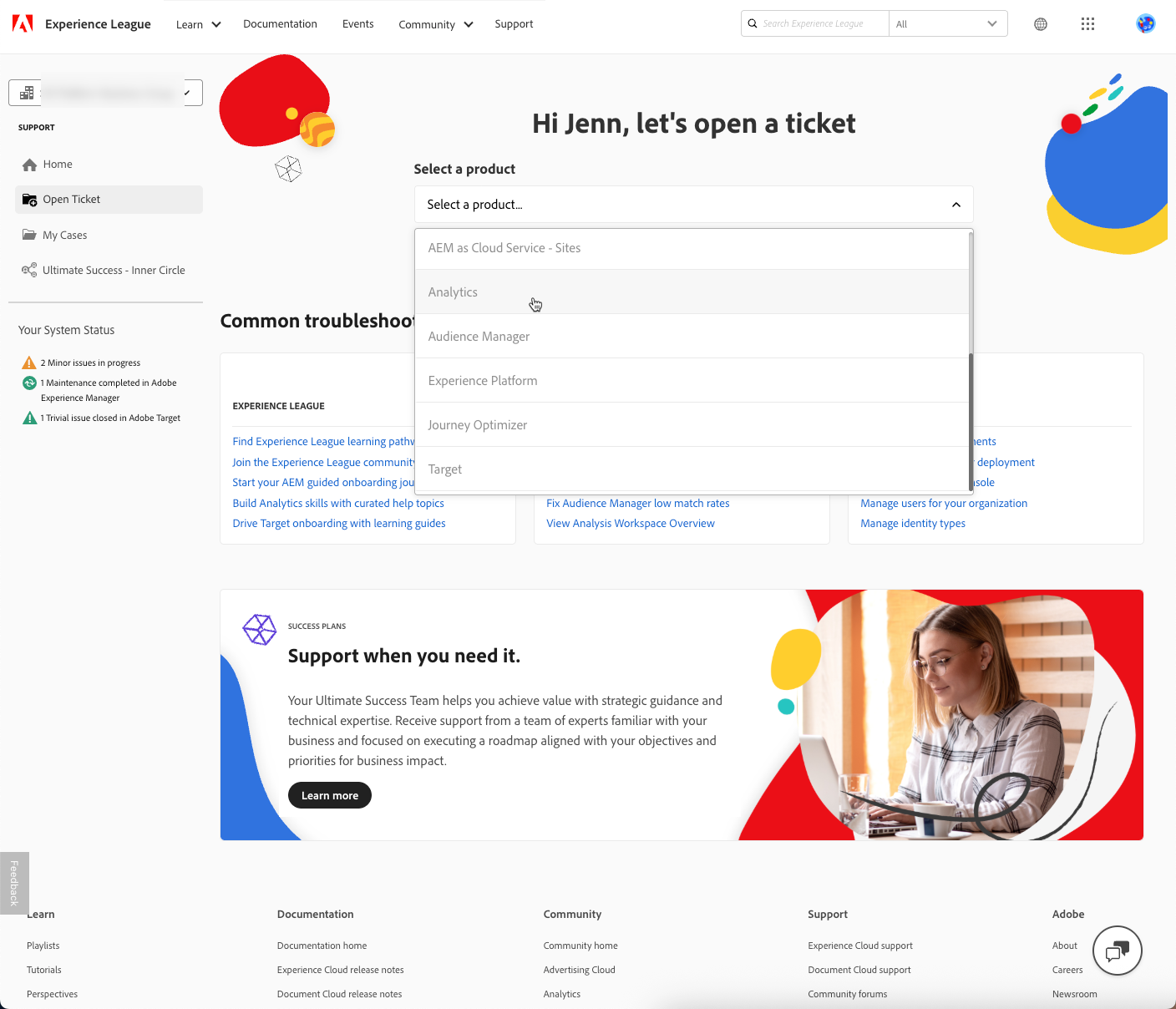
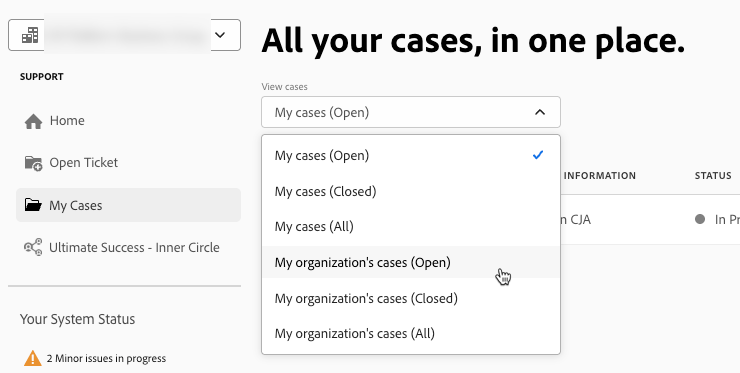
Here they can create tickets:
…and see open tickets, including tickets opened by others if they open the “view cases” drop down on the “My Cases” screen:
I was going to say they may also email customerCare@adobe.com directly to create a support ticket, but it seems that may have been decommissioned, and you must use the UI now.
I have some pretty big news: after 7 wonderful, transformational years at 33 Sticks, I’m moving on to a position as a Manager of Analytics Engineers at PlayStation (still working remotely from Georgia). I’ve been in essentially the same consulting role (analytics implementation consultant) since I started at Omniture in 2006 (shortly after I graduated college), so going client-side (much less to a Management position) is a pretty big change (and frankly, a bit scary).
To be clear, I love 33 Sticks dearly. But this was too good an opportunity pass up (PlayStation!?!), and I am excited about the change. I’m sure I’ll post later about the new role, but for now, I want to dedicate some time to the team at 33 Sticks.
33 Sticks is like my family. I don’t mean this in the cliche “this company is like family” way that gets thrown around on LinkedIn, but that in a “these people have seen me at my best and my worst and continue to love me (and vice versa)” way. We’re not perfect, and that’s ok. It’s a bunch of deeply human humans doing their best, and it works because everyone there cares so deeply- about each other, about our clients, about doing the right thing.
Leaving a company like that is hard. I’m going to miss this culture immensely. It’s a rare gift to be able to post “at the aquarium with my fam!” at 11am on a Wednesday and to not have to worry about my boss seeing that I’m taking random time off. If anything, I’d want to tag him in such a post because I knew it’d make him happy: seeing his employees living full lives and spending time with family meant he was achieving the company’s mission.
But it isn’t just Jason. Yes, Jason has quite the online presence, and I doubt anyone will be shocked to hear he’s a thoughtful, supportive boss and just a genuinely good person. Hila, the other founder, may be quieter on social media, but she’s every bit as essential to 33 Sticks. She’s a force to be reckoned with, and I love her like a sister. And I’ll miss Jim and Jon as well- Jim and I, particularly, have been through the trenches together (and I’ve loved watching his little family grow up).
33 Sticks has supported me, celebrated me, and gave me the space to grow. I’ve gotten to travel the world (and even bring my family along sometimes). I’ve been encouraged to build products and speak at conferences. They asked a lot of me, pushed me out of my comfort zone, and they treated me like a rock star. And my confidence grew immensely because of that.
Even before I started at 33 Sticks, I was saying I didn’t want to stay a consultant forever. And don’t get me wrong- even at 33 Sticks, it hasn’t always been sunshine and rainbows. But the fact that 33 Sticks kept me in consulting for 7 years (twice as long as any other job) says a lot.
I was never asked about utilization rates, and never had to mess around with time sheets. Some weeks, I’d work 30 hours, and some weeks I’d “work” 60 hours because I spent a lot of extra time going down some rabbit hole and learning about some technology that was only tangentially related to my client work. I was trusted with my time.
This trust created a culture full of unforgettable memories:
That timeI I joked my office would get more use out of a cotton candy machine than a coffee maker… and weeks later, a commercial-grade cotton candy machine showed up at my door. (We’re the coolest house on the block at Halloween.)
That time Jason and Hila, knowing how much I missed the concert harp I used to play, arranged for a harp to be waiting for me in the 33 Sticks suite during Adobe Summit. They even conspired with my husband to sneak my old harp sheet music into my luggage so I’d have something to play!
That time I was enlisted to work the t-shirt cannon when Hila presented at Summit… and I miscalibrated the pressure and blasted a shirt at the ceiling at full force, nearly taking down a chandelier in the Venetian (oops)
That time I had a major health incident on a trans-atlantic business flight and the only person I could think of who could be awake (and who I trust) was Hila (via the only channel available, FB messenger), who then worked to wake up my husband and get in touch with my travel contacts to make sure I was taken care of, all while I was still in the air.
That team dinner where we got to watch a prostitute (successfully) make her sales pitch at the bar near by (they sealed the deal with a handshake. No joke.)
All the good times at the “33 Sticks Suite” at Adobe Summit- a nice quite place anyone can come and play with puppies, eat good food, or just chill away from the craziness of the busy conference. Conferences were about PEOPLE (and puppies!), not leads and sales pitches.
All the times Jason and Hila tried valiantly to expand my palate (and I ordered the same boring steak anyway).
I love that my husband has a real relationship with my bosses (and my kids know all of my coworkers’ names and personalities). I love that when my dad died, and when my mom had various health scares, I never had to worry for a moment about the time I’d need to take off or whether or not I’d be supported. When certain world-breaking political events happened, we were given time off to be with family and protect our mental health. 33 Sticks always put the human first, in a rare and special way.
As excited as I am about this new opportunity at PlayStation, every step of the application process, I was dreading the prospect of saying goodbye to my role at 33 Sticks. Even this farewell post, I’ve been putting off, because I don’t know how to put it all into words.
Jason and Hila, you have built something truly unique here, and I’m so grateful that you made me such a big part of it. Thank you!
I’ve written previously about what I’ve found to be the most scaleable method of implementing analytics in Adobe Launch*, but that was for the old Analytics/appMeasurement way of doing things. If you’re using the webSDK, the Rule Sandwich is still an option, though it works slightly differently (and is a little less intuitive, IMO).
Before I tell you how, I highly recommend reading that previous Rule Sandwich post, but if not, at a high level, the idea behind the “rule sandwich” is to have:
1. one rule that fires everywhere, that sets all your global variables- things that follow the same logic everywhere, and belong on every (applicable) event, such as login state, site section, marketing campaign…
2. a set of rules specific to particular user actions (a product details page view, a form submission, etc) where you set variables that should only be set with that user action
3. potentially a third rule to fire the event/beacon off to Adobe.
The goal is to reduce redundancy and create something that scales. If page name is ALWAYS going to come from the same place in the data layer, there is no reason to configure that over and over. If I need to make an update to one variable, I don’t want to do it in a bunch of different rules.
The “Standard” webSDK Implementation: map your XDM Object
The “default” way (and for a long time, the only way) to setup your webSDK payload was to have a single “XDM Object” data element that mapped everything. Adobe’s documentation walks through how to do this. There is one big problem, though: some XDM fields (like anything you’d base a metric on) should only be set in certain situations- for example, I only want my Internal Search Input metric to increment “1” on the Internal Search Results page. If I had a single Data Element that handled all of my XDM set up, how do I tell it to only set _experience.analytics.event1to100.event5.value to “1” when the user is on a Search Results page? You could:
Have a data element for every metric, so you could use script to dynamically fill in that XDM field. If I have 50 events, that means I might have 50 data elements that each look something like this (or possibly more complicated depending on your conditions) :
…and then in your XDM Object Data Element, you’d do something like this for every one of your event fields:
You could create a separate XDM object for each situation. For example, you’d have a “Search Results” rule that pulls in your “Search Results” XDM Object Data Element, which has all your global variables, plus your internal-search-specific logic. Then you’d have another “Product Details Page” rule that pulls in your “Product Details Page” XDM Object Data Element, which also has all your global variables, and so forth.
You don’t set your situation-specific stuff in Launch at all, and instead use Data Prep to do something like this:
I really dislike all three of these options, though if I had to choose, I’d go with the first. Fortunately, Adobe provided another way: Update Variable.
A better option: Update Variable
To use Update Variable, you first need to create a webSDK Data Element of the type “Variable”:
This is a little unique, since it’s a Data Element that doesn’t really return something that you’d want to use, but rather just gives you abilities within your Rule Actions. The Data Element is mainly just to give you a place to specify the schema you want to follow.
Then you create rules with varying scopes, to “update the variable” as needed. At this point, you can think of it the same way you’d think of the Analytics “Set Variable” action (which can really help with migration, by the way- you can “migrate” one “Set Variables” at a time).
So, to make my rule sandwich, I’d start with a Global rule I want firing on all my events. The tricky part is covering all the different types of triggers that might fire tracking. If you’re using the ACDL extension, and not listening to any clicks or anything, then this is easy-peasy. But often it’ll end up being some combo of data layer events and clicks (and again, this is discussed in my previous Rule Sandwich post).
I’d give the trigger(s) a low “order” number (like 1, or 25… it’s all relative, just needs to be lower that my other rules). I’d create an action using the WebSDK’s “Update Variable” Action Type:
When I first open that “Update Variable” action, it will have me specify which variable I want to update, so I select the Data Element I just created. It will then create an XDM tree that matches your schema, very similar to an “XDM Object” Data Element. It even includes some helpful info, about how to tell what has been populated and how to clear out all or part of your variables as needed (which is important- we’ll get back to that later).
Since this is our global rule, I’d go through and set every field I have that should always fire, provided its data element has a value (login state, page name*, internal/external campaign tracking codes, etc).
*Note with Page Name and URL, you may not want to set that globally, particularly if this data is still bound for Adobe Analytics. Analytics bases whether or not it consider an event a “page view” (equivalent to an s.t() beacon) based on several factors, including the presence of URL orpage name.
Then I’d create my situation-specific rules (my “sandwich fillings”)- things that should only fire on certain pages or certain user actions. For instance, I might have a rule specific that fires on page load, only when my page type is ”Search Results”:
Then in my “update variables” action, I would set the fields for Search Results Term, Number of Search Results, and whatever metric I want to increment to indicate the user has made a search query:
Note, when I increment a metric, I should use the number, without quotation marks- it needs to be an integer, not a string. If the data is being fed only into Analytics then it doesn’t matter as much (it seems to handle strings and integers the same), but if the data is going into CJA, this will make it so much easier to turn it into a metric.
Finally, we need to actually fire events off to Adobe’s Edge. For page views, this is where the top slice of bread comes in: a rule, with order #100, with a webSDK “Send Event” action:
For non-page-views, I may just add that event to the existing “filling” rule. This lets me specify an event type that suits that user action. OR, I may create a different “top slice of bread”, if I have many rules all tracking something similar and I tire of adding a “Send Event” action to every single one of them. (Again, all of this is detailed in the original blog post– just swap “Set Variables” for “Update Variable”, and “Send Beacon” for “Send Event”.)
The final result should be an event payload that includes fields from your global rule and any rules where you updated your variable.
Gotchas
Clear variables
In the appMeasurement/Adobe Analytics world, we had issues with variable persistence and sometimes had to clear out our variables, and the webSDK is no different. If, for example, when my page loads, I “update my variable” to set my Search Results metric to “1” and fire an event, but then the user selects a search filter and I want to update the variable and fire an event again… that Search Results metric will still be “1” in my XDM variable. My “search filter” event payload will include my search results event, as well as any event I set earlier on that page, potentially duplicating metrics.
Fortunately, the “Update Variable” allows you to clear out previously-set fields. You can do this on a field-by-field basis, but with the Rule Sandwich setup, I find it easiest to just do it on my “bottom slice” global rule- select your top-level xdm object and check “Clear Existing Value”.
(10 points if you spot the typo in the interface)
Since you’re about to re-set all your important global variables, you don’t have to worry about erasing anything you wanted to hang around. If you are concerned about clearing something important, you can focus on clearing out the fields your metrics are based on, since those tend to be the ones we don’t want hanging around. For example, I can easily clear out most of my Adobe Analytics events by just focusing on the “event1to100” objects:
Copying between properties
We came across an interesting bug when using “Update Variable” when we tried to copy the whole set up from one Launch Property to another. We copied the XDM Variable Data Element and every rule that used it. Both properties followed the same schema and used the same datastreams, so it felt like a simple lift-and-shift. In the interface, everything looked great… but nothing worked. I was just helping out (it wasn’t my client) so I didn’t have access to the Launch properties in question, so I had to resort to troubleshooting in the code… which ended up being a good thing, because only there could I have seen the “Update Variable” action doesn’t reference the XDM Variable Data Element name, but rather, some internal ID, and that internal ID seemed to be copied from the original property.
The data element itself had one ID:
But the code for the Rule with the “Update Variables” action seemed to be referencing something else altogether:
Whereas the original property (which still worked) had the same ID (the one ending “4d3d”) in both of those spots. So our new property’s Update Variables actions were seemingly trying to reference the ID of the XDM Variable Data Element from our original property.
In my testing on my own properties, I could see that it should be as simple as giving your new property’s XDM Variable Data Element a slightly different name (in my experience, it only worked if the data element had a new name, otherwise it kept trying to reference the old ID) and going through each Update Variable Action and changing its variable to your new property’s newly-renamed Data Element. In my testing, at least, I did NOT lose the mappings I had worked so hard on when I changed my variable (hooray). It is annoying to have to do this in all your Update Variable actions, but better than starting from scratch. Make sure you also update the variable reference in your “Send Event” actions.
(Since I wasn’t technically on the account in question, I didn’t submit this as a bug to client care and I don’t know if anyone else has, but someone probably should.)
What works for you?
This is a method that has worked well for me, but (as any honest agency/consultant should tell you at this point)… we’re all still figuring this webSDK/XDM/CJA stuff out as we go. Unlike appMeasurement (and H code before it), I don’t have nearly 20 years of experience to tell you all the gotchas and to be able to say which methods will withstand the test of time. I have been on alphas/betas/POCs for the webSDK since 2019, but I only have a few XDM projects where I have been able to look back a year or two later and say “that worked well” or “I wish I had done something different”.
I’m grateful for consultants from other agencies (Adswerve and Slalom, in particular) not to mention MANY individual practitioners that have helped me puzzle some of this out. We all benefit from knowledge-sharing at this point, and one of my favorite things about this industry is how much folks generally care more about learning and sharing than they care about “competition”.
I’ll update this post if I figure anything out that’s relevant, and hope folks will reach out to me if they discover something that works better, or some other gotcha folks should be aware of.
*Still not calling it “Adobe Experience Platform Data Collection Tags”
I created this very cheesy graphic for a blog post I wrote in… 2011. That’s right, I’ve been trying to stop cookie panic for 13 years.
Update: if you enjoy this post, we did a follow-up livestream (based on a very popular presentation I gave at MeasureCamp), now available on youtube, that walks through specific examples of how cookies work (I promise, you may be surprised) and the misleading narratives we tell about consent and server-side tag management. (This is cross-posted from the 33 Sticks blog.)
I know we’re all sick of hearing about the “cookieless future”. As a topic, it somehow manages to be simultaneously boring (it gets too much air time) and terrifying (the marTech world is ending). But I want to discuss the problematic word itself, “cookieless”. I get that a lot of people use it metaphorically- they know that cookies as a general concept are not going anywhere; we just need a way to refer to all the changes in the industry. But I still argue the phrase is ambiguous at best, and misleading at worst. If someone brings up “the cookieless future” they might be talking about:
Browsers blocking or capping certain 1st party cookies (like Safari’s ITP)
Browsers and ad blockers blocking tracking technology (like Safari’s “Advanced Tracking Protection”, which blocks not just analytics, but GTM altogether)
Browsers and ad blockers blocking marTech query params like gclid or fbclid
App ecosystems blocking the use of device identifiers within apps (like Apple’s ATT)
OR Privacy and Consent Depending on your jurisdiction:
Your users may have the right to access, modify, erase or restrict data you have on them. This applies to data collected online tied to an identifier, as well as PII data voluntarily given and stored in a CRM.
Your users have the right to not be tracked until they’ve granted permission (GDPR), or to opt-out of their data being shared or sold (CCPA and many others)
Data must be processed and stored under very specific guidelines
You’ll note under the “Privacy and Consent” list, I don’t mention cookies. That’s because laws like CCPA and GDPR don’t actually focus on cookies. CCPA doesn’t even mention cookies. GDPR is very focused on Personal Information (which is broader than Personally-Identifiable Information, or PII. Personal Information refers to anonymous identifiers like you might find in marTech cookies, but it also refers to IP addresses, location data, hashed email addresses, and so on). Again, for those in the back: CONSENT IS FOR ALL DATA THAT HAS TO DO WITH AN INDIVIDUAL, NOT JUST COOKIES. Cookies are, of course, a common way that data is tied to a user, but it is only a portion of the privacy equation.
I understand why we want one term to encapsulate all these changes in the industry. And in some ways, it makes sense to bundle it all together, because no matter the issue, there is one way forward: make the best of the data we do still have, and supplement with first-party data as much as possible. However, this conflation of technology (chromeCookiePocalypse) with consent (GDPR) has led to exchanges like this one I saw on #measure slack this week:
Q: “After we implemented consent, we noticed a significant drop in conversions. How can we ensure accurate tracking and maintain conversion rates while respecting user privacy?”
A: “Well, that’s expected, isn’t it? You will only have data from those who want to be tracked. If folks opt out, you will have less data.”
Q: “Yes, we expected a dip in conversion, however our affiliates are reporting missed orders and therefore commission discrepancies, which is affecting our ranking. They suggested API tracking and also said that since they are using first party cookies, they should not be blocked, and we should categorize them as functional“.
Sigh. People are understandably confused. First-party cookies don’t need consent, right? Privacy just means cookie banners, right? Losing third-party cookies will mean a lot of lost tracking on my site, right? If we solve the cookie problem, work can continue as normal, right? (Answers: no, no, no, and no).
Even people who should know better are confused. The focus on cookies has silliness like this happening:
Sites removing ALL cookies from their site (talk about throwing the baby out with the bathwater, if baby-throwing took a lot of effort and resources)
Server-side tag management being touted as “vital for a cookieless future” (as if adding a stopping point between the user’s browser and data collection points somehow reduces the need for lasting identifiers in the user’s browser, or for consent. Server-side tag management has advantages, but it just shifts the cookie and consent issues. It doesn’t solve them. )
People thinking that a Javascript-based Facebook’s CAPI deployment will provide notable, sustained protection against online data loss (I have a whole other blog post about this I need to finish up)
Agencies selling “third-party cookie audits”, to scan your site for third party cookies and help you document and quantify each one to prepare for the impending loss of data.
I want to talk specifically about this last one. This idea (that auditing your site for cookies is a key way to prevent data loss due to Chrome blocking 3rd party cookies) has been a key talking point at conferences, has been promoted by agencies and vendors selling their 3rd-party-cookie-auditing services, and is even promoted by Google’s don’t-panic-about-us-destroying-the-ad-industry documentation.
But all the ChromeCookiePocalypse dialog- and the cookie audit recommendations- leaves out critically important context (especially if we’re talking to an audience of analysts and marketers):
Between Safari, Firefox, Opera, and Brave (not to mention ad blockers), 3rd party cookies have not been reliable for some time. There is a good chance more than 50% of your traffic already blocks them, and the world continues to turn, partially because of so much mitigation that’s already been done: Adobe Analytics, Google Analytics, Facebook, Adwords, Doubleclick, etc… all already use 1st party cookies for tracking on your site (that “on your site” bit is important, as we’ll discuss in point #4).
That said, we can’t pretend that if we fix/ignore the 3rd party cookie problem, then our data is safe and we can continue business as usual. Yes, 3rd party cookies are being blocked, but even 1st party cookies may be capped or limited because of things like Apple’s ITP. Some browsers and/or ad blockers may block tracking even if it’s first-party. And there are other issues: bots are rampant on the web and most tools do a poor job of filtering them out. Browsers strip out query parameters used to tie user journeys together. Depending on your local privacy laws, you could be losing a significant portion of your web data due to lack of consent (I’ve seen opt-out rates up to 65%). All data collected online is already suspect. I suppose it’s better late than never, but even if Chrome weren’t changing anything, you should already be relying on first-party data wherever possible, supplementing with offline data as much as possible.
A thorough audit of 3rd party cookies is not going to tell you what you need to know. I, as a manager-of-tags tasked with such an audit, can tell you your site has a Doubleclick cookie on it. I can’t tell you what strategies go into your Doubleclick ads. I can’t tell you how much of your budget is used on it. I can’t even tell you if anyone is still using that tracking. I can’t tell you from looking at your cookies how your analysts use attribution windows, or if you currently base decisions off of offsite behavior like view-through conversions. I can’t tell you, based on your cookies, if you have a CDP that is integrated with your user activation points. Even if the cookies alone were the key factor, a scan or a spot-check of your own site is likely to miss some of the more important cookies. If I come directly from Facebook or Google to a site, then I may have cookies that wouldn’t be there if I came directly to the site. If I’ve ever logged in to Facebook or Google within my browser, that will add even more 3rd party cookies on my site. It would be virtually impossible to audit all of those situations to find all of those cookies, but it’s THOSE cookies that matter most. Because…
...it’s the cookies that will go missing from *other* websites that will have the biggest impact. Where the ChromeCookiePocalypse gets real is for things like programmatic advertising, or anything that builds a user’s profile across sites, or requires a view into the full user journey. Accordingly, the 3rd party cookies on your own site might not be nearly as important as the cookies on other places on the web that enrich the profiles of your potential audience.
I think the reason I’m so frustrated by the messaging is because 1, I hate anything that resembles fear-mongering (especially when it includes the selling of tools and services), and 2, I’ve already seen so much time focused on painstaking cookie audits that don’t actually move an org forward. Focusing on the cookies encourages a bottom-up approach: a lot of backwards engineering to figure out the CURRENT state, rather than taking the steps towards 1st party data… steps that you should be taking regardless. Finding a 3rd party Facebook cookie on your site shouldn’t be how you find out your organization uses targeted advertising, nor should it be the reason you update your strategies. I wonder how much the push to scan websites for cookies and create spreadsheets is because that task, tedious as it is, sounds much more do-able than rethinking your overall data strategy?
If you’re afraid something has slipped through the cracks, then yes, do a cookie audit: go to a conversion point like a purchase confirmation page and look at the 3rd party cookies. Before you research each one, just note the vendors involved. Just seeing that a 3rd party cookie exists gives you a heads up that you have tracking on your site from a vendor that relies on 3rd party cookies for some part of their business model. Because if they’ve got a 3rd party cookie on your site, odds are they use that same cookie on other sites. That’s what you need to solve for: how will your business be affected by your vendors not collecting data on other sites? Don’t focus on the cookie, focus on your strategies. What technology do you have that relies on cross-site tracking? How much of your advertising budget is tied to behavioral profiling? Programmatic advertising? Retargeting? Does your own site serve advertisements that use information learned on other sites? Does your site do personalization or recommendations based on user data collected off your site? What 1st party data do you currently have that could be leveraged to fill in gaps? How can you incentivize more users to authenticate on your site so you can use 1st party identifiers more?
Talk to your marketers and advertising partners. Don’t ask about cookies. Ask what advertising platforms they use. Ask about current (or future) strategies that require some sort of profile of the user. Ask about analysis that requires visibility into what the user is doing on other sites (like view-through conversions, if you still think that’s useful, though you probably shouldn’t). Ask about analysis that relies heavily on attribution beyond a week (which is currently not very reliable and likely to become even less so.)
And, most importantly, talk to the vendors, because it’s going to be up to them to figure out how their business model will work without 3rd party cookies. Most of them will tell you what we already know, but may not be ready to make the most of: 1st party data is the key (which usually means supplementing your client-side online data with data from a CDP or other offline databases). Ask what options there are to supplement client-side tracking with 1st party data (like Meta’s Conversions API). Ask how they might integrate with a Customer Data Platform like Adobe Experience Platform’s Real-Time CDP.
I’m not arguing that we don’t need to make some big changes. In fact, I’m happy the ChromeCookiePocalypse pushed people into thinking more about all of this, even if it was a bit misguided. Technology is changing quickly. Consent is confusing and complicated. Analysts and marketers are having to quickly evolve into data scientists. It’s a lot to keep up with. But words are important, and it’s not just about cookies anymore. Welcome to the “consented-first-party-data future”*.
*I’m open to suggestions for other “cookieless” alternatives
Adobe’s Opt-In Service is a tool provided by Adobe to help decide which Adobe tools should or should not fire, based on the user’s consent preferences. It has some advantages I don’t see folks talk about much:
It manages your Adobe tags (Analytics, ECID, Target) at a global level. If you’ve got it set up right, you don’t need to make any changes to your logic that sets variables and fires beacons (you don’t need a ton of conditions in your TMS)- any rule’s Analytics or Target actions will still run, but not set cookies or send info to Adobe.
When your existing variable-and-beacon-setting logic runs while the user is opted out, Adobe queues that logic up, holding on to it just in case the user does opt in. Any Adobe logic can run, but no cookies are created and no beacons get fired until Adobe’s opt-in service says it’s ok.
This latter point is very important, because in an opt-in situation, frequently consent happens after the initial page landing – the page that has campaign and referrer information. If you miss tracking on that page altogether, you will lose that critical traffic source information. Some folks just re-trigger the page load rule, which (depending on how you do it) can mess up (or at bare minimum, add complexity) to your data layer or rule architecture. So I’m a big fan of this “queue” of unconsented data.
You can even experiment and see for yourself- this site has a globally-scoped s object, and an already-instantiated Visitor object. Open the developer console, keep an eye on your network tab, and put this in, to opt out of analytics tracking on my site:
adobe.optIn.deny('aa');//opt out analytics
Then run code that would usually fire a beacon:
s.pageName="messing up Jenn's Analytics data?" //you can tell me a joke here, if you want
s.t()
No beacon!
Now let’s pretend you’ve clicked a Cookie Banner and granted consent. Fire this in the console:
adobe.optIn.approve('aa');//opt in analytics
And watch the beacon from earlier appear! Isn’t that magical?
Side note: The variables sent in the beacon will reflect the state when time the beacon would have fired. I tested this- if I do this sequence:
adobe.optIn.denyAll()
s.prop15="firstValue"
s.t() //no beacon fires because consent was denied
s.prop15="secondValue"
adobe.optIn.approveAll() //now my beacon fires
…the beacon that fires will have prop15 set to “firstValue”- it reflects things at the time the beacon would have fired.
To re-iterate: if you have the ECID service set up correctly, it will still look like your Analytics/Target rules fire, but the cookies and beacons won’t happen until consent is granted.
How to Use within Adobe Launch*
Most of Adobe’s documentation assumes you’re using Adobe Launch*, and even then, leaves out some key bits. The Experience Cloud ID extension has what you need to get things set up, but is not the complete solution (you can skip this and go straight to the Update Preferences section below if you want the part that’s not particularly well documented). Let’s walk through it, end-to-end:
Opt-In Required
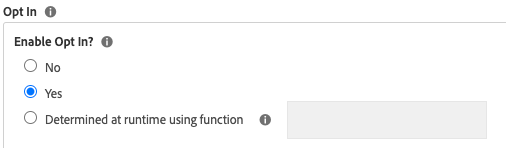
First, tell Launch when to require Opt-in.
If it’s just “yes” or “no”, then it’s simple enough. If you want to decide dynamically (based on region, for example), then you need to create a separate Data Element that returns true or false. For example:
if(_satellite.getVar("region")=="Georgia"){
return false //Georgia doesn't care about consent. Yet.
}else{
return true
}
To be honest, to me it’s always made more sense to just click the “yes” option, then further down, change up people’s default pre opt-in settings based on region.
Store Preferences
I’ll admit, I’ve never used these, but I think they’re self-explanatory enough: the ECID is offering to store the user’s consent settings for you. This seems convenient, but I’ve never seen a set up where the overall CMP solution doesn’t already store the consent preferences somewhere, usually in a way that is not Adobe-specific.
Previous Permissions/Pre Opt In Approvals:
The “Previous Permissions” and “Pre-Opt-In Approval” settings work very similarly, but “Pre-Opt-In Approval” is more of a global setting, and “Previous Permissions” is user-specific (and overwrites “Pre-Opt In Approval”). In other words: Pre-Opt-In Approval settings are used when we don’t have Previous Permissions for the user.
The key here is the format of the object, usually in a Custom Code Data Element, that Adobe is looking for:
{
aam:true,
aa:true,
ecid:true,
target:true
}
…where true/false for each category would be figured out dynamically based on the user. So your data element might have something like this:
All of the above is great for when the ECID extension first loads. But what about when there is a change in the user’s preferences? As far as I know, this can’t be done within the ECID extension interface, and it’s not particularly well documented… this is where you have to use some custom code which is kind of buried in the non-Launch optIn service documentation or directly in the Opt-In reference documentation. (I think we’re up to 4 different Adobe docs at this point?)
When your user’s preferences change, perhaps because they interacted with your banner, there are various objects on adobe.optIn that you can use:
adobe.optIn.approve(categories, shouldWaitForComplete)
adobe.optIn.deny(categories, shouldWaitForComplete)
adobe.optIn.approveAll():
adobe.optIn.denyAll():
adobe.optIn.complete(); //have adobe register your changes if you set shouldWaitForComplete to True
The “shouldWaitForComplete” bit is a true or false- if true, then Adobe won’t register your changes until you fire adobe.optIn.complete(). If false, or omitted, then Adobe will immediately recognize those changes.
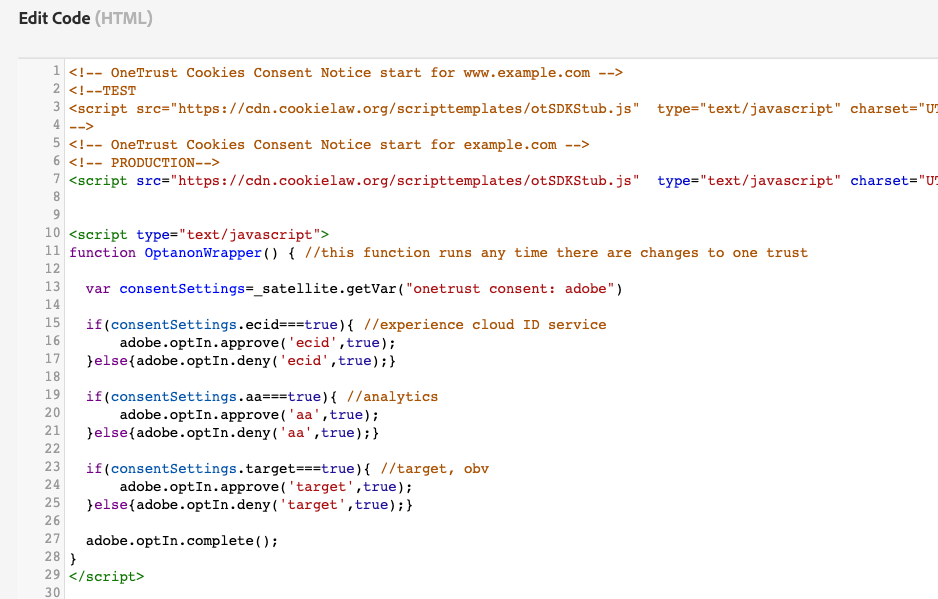
So I might have a rule in Launch that fires when the user clicks “approve all” on my banner (or if I’m using oneTrust, within their OptanonWrapper function), with a custom code action that looks something like this:
adobe.optIn.approve('target',true);//opt in target
adobe.optIn.approve('aa',true);//opt in analytics
adobe.optIn.approve('ecid',true);//opt in the visitor ID service
adobe.optIn.complete();
Which could also be accomplished like this:
adobe.optIn.approve(['target','aa','ecid']);
Or even just this (in my tests, this did not require adobe.optIn.complete()):
adobe.optIn.approveAll();
What if I’m Not Using Launch?
If you’re not using the Launch ECID extension, then the initial stuff- the stuff that WOULD be in the extension, as detailed above, is all handled when you instantiate the Visitor object. This is all covered Adobe’s Opt-In Service documentation, which I personally found a bit confusing, so I’ll go through it a bit here.
As far as I can tell, this bit from their documentation:
adobe.OptInCategories = {
AAM: "aam",
TARGET: "target",
ANALYTICS: "aa",
ECID: "ecid",
};
// FORMAT: Object<adobe.OptInCategories enum: boolean>
var preOptInApprovalsConfig = {};
preOptInApprovalsConfig[adobe.OptInCategories.ANALYTICS] = true;
// FORMAT: Object<adobe.OptInCategories enum: boolean>
// If you are storing the OptIn permissions on your side (in a cookie you manage or in a CMP),
// you have to provide those permissions through the previousPermissions config.
// previousPermissions will overwrite preOptInApprovals.
var previousPermissionsConfig = {};
previousPermissionsConfig[adobe.OptInCategories.AAM] = true;
previousPermissionsConfig[adobe.OptInCategories.ANALYTICS] = false;
Visitor.getInstance("YOUR_ORG_ID", {
"doesOptInApply": true, // NOTE: This can be a function that evaluates to true or false.
"preOptInApprovals": preOptInApprovalsConfig,
"previousPermissions": previousPermissionsConfig,
"isOptInStorageEnabled": true
});
Could be simplified down to this, if we skip the extra OptInCategory mapping and the preOptInApprovalsConfig and previousPermissionsConfig objects:
Literally, that’s it. That’s what that whole chunk of the code in the documentation is trying to get you to do.
Beyond that, updating preferences happens just like it would within Launch, as detailed above.
Side note- what’s up with adobe.OptInCategories?
I’m not sure why Adobe has that adobe.OptInCategories object in their docs. These two lines of code have the same effect, but one seems much more straightforward to me:
The adobe.OptInCategories mapping is set by Adobe- despite it being in their code example, you don’t need to define it, it comes like this:
I’m guessing this was to make it so folks didn’t have to know that analytics is abbreviated as “aa”, but… if you find the extra layer doesn’t add much, you can bypass it entirely if you want.
Conclusion
Once I understood it, I came to really like how Adobe handles consent.
I am by no means considering myself an expert, or trying to make a comprehensive guide. But the documentation is lacking or spread out, so most of this took some trial and error to really understand, and I’m hoping my findings will prevent others from having to do that same trial and error. That said, I’d love to hear if folks have experienced something different, or have any best practices or gotchas they feel I left out.
*still not calling it “Adobe Experience Platform Data Collection Tags”
I’ve mentioned before how much I love that Launch* can “stack” all sorts of rules- by which I mean multiple rules of varying scopes can combine together into a single analytics beacon.
This means (using an example from that old post) I can have a global rule that sets my universal variables, a rule for search results, a rule for filters, a rule for null search results, and a rule that fires the beacon, all resulting in a single beacon where all the variables might be coming from a different rule. I call this a “Rule Sandwich”:
That particular example may be a bit overkill, but this ability to divide up your variables by scope can be key to a scaleable implementation.
Don’t Repeat Yourself (DRY): If you can find a single place to set a variable, do it. Don’t set site section in every page that has a site section- set it in a global place that can dynamically set the right value from the data layer.
Keep It Simple, Stupid (KISS): Daisy-chaining Direct Call Rules can quickly complicate an implementation and introduce multiple points of failure. Huge Switch statements in code can make it hard to find specific dimensions or events.
Principal of Least Astonishment: People who encounter your setup shouldn’t have any surprises. If the next person who signs in to your Launch property says “oh, wow” or needs a “eureka” moment, you may have over-engineered things.
Following those principals, here’s the “Sandwich” set up I most like to use:
The bottom slice: Global Variables
My first rule sets my universal variables- things like site section, campaign, login state, user ID, etc. Stuff where I can say “if it exists in the data layer, I want it in my beacon”. It is set up to fire on all triggers that might end up in an analytics beacon. If you’re using the Adobe Client Data Layer extension and all your rules are triggered by your ACDL data layer, then this can be pretty simple, thanks for “Listen to All Events”:
But I’ve also had setups like this:
I add “#1” to the trigger name and rule name to indicate that these are triggered with a rule order of 1:
Which means for any given trigger**, this will be the first rule to fire. In this rule, I set any variables that can be applied globally- usually things like page name, site section, page type, language, etc.
**A note about sequencing: the order for rules only applies when rules share a common trigger. If you have a rule that fires on DOM Ready, and a rule that fires on a “page view” event in your data layer when DOM Ready occurs, even if they happen at the exact same time, Launch won’t compare their order to see which comes first. The rules would either both have to be triggered on DOM Ready, or both triggered on the “page view” event.
The Analytics extension does a great job of keeping everything in sequence. In other words, if I have a rule with an order of 1 that sets analytics variables I can be confident that a rule with the same trigger with an order of 50 will apply its analytics variables only after the first rule has finished. (However, Custom Code blocks will not wait for earlier-ordered custom code blocks from other rules to finish. If I have a rule with an order of 1 that runs some script in a custom code action, I can’t know for sure that script will have finished before code in a separate rule with an order of 50 happens.)
You might ask “Why don’t you use the Adobe Analytics Extension’s global variables?”
The problem with these is they only evaluate once, when the extension first kicks in on page load (go upvote my idea if you, too, want it to behave differently). So if you clear variables, they disappear and won’t come back until the next page load. And if you try to pass new values- maybe the language preference changed, or maybe you have a SPA and need to pass a new page name- the extension won’t pick those up.
Many folks use the doPlugins function for this purpose, because it fires on every beacon. There’s a few reasons I avoid this when I can:
I try to keep my variables out of code as much as possible- the more transparency in the interface, the better.
I try to keep doPlugins light. With default settings, it runs on every click, whether that click results in a beacon or not.
doPlugins is the LAST thing to fire before a beacon is sent to Adobe, meaning any customization I’ve done in other rules might be overwritten.
Which brings me back to my #1 rule that fires on all of my common triggers. I set my global variables, and that’s it- no sending a beacon (yet).
The middle of the sandwich- the “fillings”
Next come all my sandwich fillings: the rules that set variables based on more specific scenarios. Any logic that needs to only fire under certain conditions go here. It’s where I set events, set any user-action-specific dimension, and hard code any values.
These rules might be triggered by a page view under certain conditions (like “pageType of article”), or based on a specific event or element interaction.
So I might have a rule that fires on page view if the page type is equal to “article”:
(In theory, I could set something like content.title in my global variables rule, because it will only set if the data layer currently has a value, but I’d rather keep all my blog stuff together and not make my global rule evaluate data elements unless they’re needed.)
I may also use these rules to customize/fix anything that had been set in my global variables. In an ideal world, data layers would be perfect and we’d never have to “fix” anything in Launch. But this isn’t that ideal world. My global variables might set the page type as “search results”, then later I realize our other search results page has a page type of “search”. Obviously, I should go to the devs and ask them to make it consistent. But in the meantime, I can use an “filling” rule to overwrite what was set in my global variables rule.
Not everything merits its own rule. If the scope only calls for a single extra event to be set, I could probably just do that in my global rule with a conditional JavaScript statement. But something like Purchase Confirmation, which has its own product string, purchaseID, etc… that makes sense as an “filling” rule. I try to find a balance between not having too many rules, and not having any single rule be super complicated.
The top slice: Send Beacon and Clear Vars
For any situation where many rules might all contribute to the same beacon- for example, page views- you can have the top piece of the sandwich as a rule with an order of 100, which fires the beacon and clears the variables.
If you have global page view variables- stuff you want on all page views but not necessarily all beacons- you could also put them here.
Note, splitting the “set variables” (our fillings) and the “send beacon” (our top slice) like this makes the most sense in a situation where you’ll have many potential rules all needing a beacon. Page Views is the best use case. Having a single separate “Send Beacon” rule makes it so if you have a few dozen page-specific Page Load rules, you don’t have to add the beacon and the clear vars action to all of them. It’s a time-saver, and a way to guarantee whatever the combination of filling rules, a single beacon will fire.
But in cases where there’s just one rule contributing to a beacon- something like a certain button click, for instance- then there isn’t much advantage to having a single “set variables” rule and a separate single “send beacon/clear vars” rule. You can combine your “fillings” and your “top slice” into a single rule, like this:
Clear Variables makes sure that variables (and particularly events) from earlier beacons won’t accidentally get attached to something they don’t belong to. Different folks handle “Clear Variables” differently. Some people set it at the beginning of rules (or sequences of rules). I find it easiest to always set it any time I fire a beacon, so I don’t have to worry about where in the sequence of things I’m clearing my variables.
Put It All Together (Examples)
Following this approach, my rules list might look like this:
(I tend to not put “#50” in the name of rules- it’s the defaultiest option; it can be assumed if no other order is specified. I also don’t specify “clear vars” in rule names anywhere- to me, it’s implied with any beacon being sent. See my post about rule naming conventions.)
On my search results page (which fires on a “page view” ACDL event where page type=”search results”), these rules would fire, in this order:
All Events | ACDL Any Event | Analytics: Set global vars #1
Search Result Views | ACDL Page View | Analytics: Set vars (#50)
All Page Views | ACDL Page View | Analytics: Send s.t, clear vars #100
On a Search Filter click, the following would fire:
All Events | ACDL Any Event | Analytics: Set global vars #1
There are, of course, many “correct” ways to architect a TMS; this is just the one that has worked best for me across many organizations, particularly if they have a reliable event-driven data layer. I will say, it can get complicated if you’re using a wide variety of rule triggers, like page bottom, clicks on this but NOT clicks on that, form submission, element enters viewport, etc… the” “Top Slice”/Global Vars Rule’s list of triggers can get very unwieldy. And sadly, if you have a very Direct-Call-Rule-based implementation, since there is no out-of-the-box “fire on all direct calls”, you may find resorting to doPlugins is the simplest, most scaleable route. Your mileage may vary.
I’d love to hear what has worked for others!
No AI was used in this post. Images are good old-fashioned paid stock images.
*I’m still not going to call it “Adobe Experience Platform Data Collection Tags”.
In my post on setting up Onetrust, I mention how problematic Autoblock can be, but it comes up often enough that I decided it merited its own post, because enabling any Consent Management Platform (CMP)’s Autoblock functionality is a big deal, with far-reaching implications.
There are two approaches to consent management:
Use your Consent Management Platform to create banners and keep track of user’s consent status. The CMP doesn’t affect what tags fire at all, it merely keeps track of user’s consent. Then you use your Tag Manager to get info from the CMP about what has been consented, then use conditions in your marketing tag rules, and the ECID opt-in service for Analytics and Target, to determine what tags are ok to fire.
Use the Consent Management Platform to create banners, track user’s consent status, and block any files or cookies that try to load without consent. Your Tag Management System has essentially no control. You don’t have to mess with extra conditions in Launch (which some see as a perk), but someone has to maintain the CMS so it knows which scripts and cookies to allow to fire.
“Autoblock” is what we call that CMP functionality that proactively blocks any non-consented technology from loading. Instead of counting on you to manage which vendor code gets to run, it lets you run all your tag code, then it just blocks any non-consented files or cookies from actually loading.
While that post was specific to OneTrust, this is actually relevant for most Consent Management Platforms. I know for sure Cookiebot, Osano, Trustarc and Ensighten can use it, and I’m pretty sure every other CMP does too, because it lets their salespeople say that setting up their tool “takes no effort at all!”
Call it what it is: consent management is complicated
We often get ourselves in trouble in our industry by thinking a simple solution will solve a complicated problem. But simple solutions often require complicated workarounds to actually work in the real world. Going with the “simple” solution may actually create more work and more points of failure.
The alternative to using Autoblock is to use the consent preferences gathered by your CMP to create conditions in your TMS to decide which vendor’s code gets to run. This sounds like more work, and sounds more prone to human error, but after reading this post I hope you’ll understand that Autoblock doesn’t remove human effort (and the possibility for error), it just shifts it.
Part of the complexity comes from the fact that for all CMPs I’ve worked with, Autoblock doesn’t just block cookies, it blocks scripts that might be setting cookies. The theory behind this is sound enough: privacy compliance shouldn’t just be about cookies, it should be about data collection. Lots of tracking can happen without cookies, and cookie names can change even if script locations do not. If a user hasn’t consented to Analytics tracking, we don’t want to just block my Adobe AMCV cookie, we want to block the appMeasurement script from trying to identify me and build beacons about my user experience. So even though everyone talks about CMPs in terms of cookies, and even most consent banners only really mention cookies, we’re usually talking about much more. Just to drive it home, because this is key to understanding how CMPs work: CMPs affect scripts AND cookies.
Also, Autoblock is a binary thing: though you can have a “hybrid” approach that uses both TMS conditions and Autoblock, Autoblock is either on (and potentially affecting everything) or off (leaving it entirely up to your TMS).
Now we’re clear on that, let’s talk about reasons to avoid Autoblock (regardless of which Consent Management Platform you use). Each CMP implements Autoblock slightly differently, and some approaches work better than others, but they all have some common pitfalls.
Complication #1: Many Points of Failure
As I said in my other post, most problems I’ve seen with CMPs have been because of Autoblock functionality. In fact, I have only seen one deployment where it didn’t cause any major problems. Even though consent management is NOT my main role, I somehow keep hearing about Autoblock issues:
In a client’s Osano POC, we saw consented analytics beacons firing in duplicate or triplicate with no explanation, inflating our Analytics data.
That same POC caused a bunch of JavaScript errors, even on site-essential scripts, because Autoblock was changing the order things loaded in or the speed in which they loaded.
One org I know of lost 2 months of consented Adobe Analytics data because of a misconfiguration in Ensighten. They didn’t lose ALL data, or they would have spotted the problem sooner- they just thought they had abysmally low opt-in rates, not that 30% of their data was blocked even when users opted in.
Another org using Cookiebot has a consumer lawsuit on their hands because an old Adobe visitorApi.js file somehow snuck through their Autoblock.
Just now, trying to test out just how OneTrust would handle AudioEye, nothing I did could get my AudioEye Script to fire if Autoblock was on. (The problem may very well have been user error- I didn’t spend too much time troubleshooting.)
A week or two back, I was brought into a call with a non-client to discuss a timing issue that was causing cookies to be created even with Autoblock on. The vendor had suggested a manual workaround that involved writing a lot of custom code to manually manipulate cookies.
The next day, someone else reached out in response to my OneTrust blog post to let me know they had just discovered that because of an issue with hashing, their Autoblock file had exploded in size, causing a sudden traffic deflation issue and impacting their page performance for months. It took a lot of resources to track down the issue, and even then they might not have spotted it if they hadn’t been running regular Observepoint scans.
Time and time again, I see troubleshooting and maintaining Autoblock taking more resources than a TMS-condition-based approach would. Again, I’ll admit a number of these problems could have been from user error. But users do err.
Regardless of the CMP, Autoblock functionality requires some sort of inventory of all the cookies and scripts your marTech vendors may be using, so that it can know what to block and what to allow. This is often where most of the “work” of maintaining a CMP comes from. There is usually some list of all possible cookies on your site that someone is going to have to sort through and maintain. Such lists can take a lot of effort and knowledge to maintain. I’ve seen these inventory lists get hundreds of items long and require weekly upkeep, forcing orgs to shift their efforts from making sure they’re using their data in compliant ways, to doing detective work on where obscure cookies like “ltkpopup-session-depth” come from and whether or not they are necessary for your site to function.
Some CMPs allow you to filter this list down to the user, so by clicking through somewhere on your banner, the user can see documentation on all the types of cookies possibly set on your site:
I am not a lawyer, but a bit of research seems to suggest this is not legally required by GDPR or any of the other major regulations (though I’ll admit there may be some reasons lawyers want you to). In fact, from my non-lawyerly view, such lists may be a liability because keeping it 100% accurate would be very difficult for most sites. So I don’t actually see this in-depth public-facing cookie documentation as a worthy benefit.
Editing to add in February 2025: As part of my Privacy Theater presentation, I demonstrate how our approach to cookies differs from how cookies work in the real world. Once you see the real world application, you’ll look at cookie inventorying very differently, I promise:
Ok, back to my original post:
Most CMPs (including OneTrust) will scan your site and let you know what cookies and scripts it found. Some may fill in some knowledge- for example, OneTrust’s Cookiepedia knows that “_gcl_aw” is likely tied to Adwords and belongs in the Marketing category- but others may rely entirely on you to categorize each cookie appropriately. Some CMPs may only look at cookies and scripts set by your site; others (like one TMS/CMP that rhymes with “enlighten”) may make you categorize all cookies and scripts that a user’s browser extensions may be bringing with them- things that have nothing to do with your site (or what you’re liable for).
One reason keeping such an inventory is so difficult is the often-unclear relationship between scripts/cookies and what purpose they serve. The marTech vendors don’t make it easy- because of acquisitions, concern about optics, or any number of other reasons, most vendors use multiple domains and set multiple cookies which often don’t have a clear association with their vendor. As part of my Tagging Overload presentation last summer, I made an inventory of 200+ common domain/vendor associations but even that is far from comprehensive (and probably far out of date by now). And if cookies are set on your own domain, it can be even harder to know if they require consent, or if your own developers use them to make your site function properly. Miscategorization could mean a lawsuit, or it could mean broken website functionality.
Let’s take two examples:
Many sites use a tool called AudioEye, which makes a site more accessible (for instance, by making it easier for Screen Readers to describe content to blind users) to stay compliant with regulations from the American Disabilities Act (ADA). I’m not a lawyer, but a strong case could be made for AudioEye being considered Strictly Necessary and therefore not require opt-in.
To add AudioEye to my site, I essentially just add a couple lines of code that reference a single .js file (https://ws.audioeye.com/ae.js). That file then brings in a bunch of other files:
Between those scripts, a few cookies get set. OneTrust picked up these third-party cookies in its scans:
(Though it did not seem to pick up on the first-party _aeaid cookie so I may need to flag that myself.) These cookies and domain are not currently in OneTrust’s Cookiepedia, and/or are incorrectly categorized as Marketing cookies. So now, instead of keeping track of the single line of code I added to the site, I’ve got a dozen+ javascript files, 5 third-party cookies, and 1 first-party cookie, for a single vendor. I’m going to need to make sure that Autoblock knows that these are all “Strictly Necessary”, not for marketing or targeting.
Let’s look at Facebook for a Marketing Pixel example next: the pixel script they give me loads one JS file, fbevents.js. But that file actually loads another file from “connect.facebook.net/signals/config/”. On the site I’m currently looking at, between those two files, Facebook sets four third-party “.facebook.com” cookies (“usida”, “fr”, “wd”, and “datr”) and one first-party cookie (“_fbp”).
If I’m relying on my TMS conditions to manage tags based on consent (instead of Autoblock), I can nip that all in the bud by not letting the code that loads that fbevents.js file to ever run to begin with. I don’t need to know that Facebook uses multiple JS files and sets a _fbp cookie on my domain- I just don’t run the script that might set any cookies to begin with.
By contrast, with most Autoblock set ups, the CMP might let me know it found two FB scripts, 4 third-party cookies and 1 first-party cookie on my site. It might suggest categorizations for known cookies for me (OneTrust is pretty good about that; some other CMPs are not), or it may count on me to know which categories they belong to, and which cookies are “strictly necessary” or not. I’d need to keep this list updated- whether or not I’m changing the tags on my site, Facebook might start setting cookies under a different name.
From what I can tell (because it’s not transparent in the interface), OneTrust then finds the scripts setting those cookies and blocks those scripts. I can’t really categorize the scripts themselves in the OneTrust interface. While other CMPs may focus on the scripts and not the cookies, OneTrust’s cookie-centric approach leaves me with very little control in the interface of which scripts I want to have fire.
(To be fair, if Autoblock blocked the fbevents.js file, it would stop all the rest from happening… but the cookie inventories seldom understand that nuance, so you still have 5+ cookies and 2+ scripts to categorize.)
But even once this list is in place and correct, you still may need to do more work to get it to work with your site.
Some CMPs, like OneTrust, use a one-size-fits-all approach: things are either on “strictly necessary” or they get blocked. You can categorize cookies as strictly necessary or not, but as far as I can tell, there is no where within the OneTrust interface to tell it a script is necessary (and if my AudioEye javascript is blocked, then it doesn’t matter that I’m allowing AudioEye to set cookies.) Instead, if I need to allow a script, I can add a custom attribute to the html of the tag:
(This goes to show: never believe a vendor that says you can implement their solution without developer work. It’s too good to be true that you could become compliant, not break your site, and not have to talk to a developer.)
Govern Tags, Not Cookies
You can be privacy-compliant without a complete list of third-party cookies. Don’t get me wrong, such a list could be handy, especially if you can keep it accurate and up-to-date. And by all means, you should have some sort of inventory of the tags on your site.
If you know what tags you are firing on your site, you can stop tracking at the source, by stopping those tags. Would you rather take the time to have a condition on your Salesforce tag in your TMS that stops it from ever firing, or take the time to find out that cookies on “cdn.krxd.net” come from Salesforce? There’s no magic bullet solution, either way.
Complication #3: Ownership
Most companies are struggling to find the right owner for maintaining a CMP. Lawyers know the regulations but may have no clue what an AMCV cookie does; marketers may know that they are using TradeDesk for advertising, but have no idea that it uses the domain adsrvr.org; developers may know that the third-party scripts from fonts.googleapis.com affect the visual appearance of the site and have nothing to do with marketing, but have no clue about Facebook cookeis.
I won’t pretend that moving away from Autoblock will clear up all the ownership issues. BUT, when the person deploying the tag (in the TMS) also has primary control of not firing the tag (via conditions in the TMS), it does simplify things.
Complication #4: No Nuance in Categories
For OneTrust at least, Autoblock is all-or-nothing; from what I understand, there are no categories beyond “strictly necessary” and “not strictly necessary”. Someone can’t opt for Analytics tracking but no Marketing tracking.
Complication #5: Timing
If you don’t have OneTrust’s library loading early enough, it may not be there in time to block early-loading scripts and cookies, leaving you with incomplete coverage. Whereas TMS conditions can have some defaults built in that don’t rely on the OneTrust script having been fully loaded (I write about one way to do that in my other post).
Complication #6: It can needlessly lose Adobe Data by not taking advantage of features like the Adobe Opt-In Service or Google Consent Mode
For Adobe Analytics tracking in a opt-in-only scenario, Autoblock limits the advantages of using the ECID Opt-In Service. The ECID Opt-In service doesn’t just kill any tracking until you have consent- it kind of holds “preconsented” tracking to the side, so once the user DOES consent, you don’t lose that data that would have been sent when the page loaded. If you’re relying only on Autoblock, you can never get that pre-consented data back. You’d need to re-run any logic that would have fired on your page view. Read more about this advantage of the ECID service in a followup post.
Edited to add, February 2025: This also applies to Google Consent Mode’s “cookieless pings.”
Complication #7: Page Performance
Autoblock has the potential to have a major impact on page performance, though this varies widely by CMP vendor. Depending on how they work, they may be adding a “gate keeping process” to every asset that loads on your site.
I haven’t tested OneTrust, but I did test another CMP’s autoblock feature and found it slowed the page’s load time up to 40%! (To be fair, I do think it was an inferior tool and hopefully other CMPs aren’t that bad.)
This is a very hard thing to test- did any changes in performance come about because of tags/scripts not firing, or because of the inherent weight of the CMP library, or because of Autoblock? I’d love to hear if any one else has found a good way to test or observed any changes in performance based on Autoblock functionality.
On the other hand, one case FOR Autoblock:
There is at least one situation in which you may need to rely on Autoblock: if you have any scripts or cookies you need to block that are NOT managed by your TMS. In order to use a condition-based approach, you have to be able to add some conditional logic to every script that needs consent. Autoblock doesn’t care if a script comes from your TMS or not- it applies to everything. If you are not confident that your TMS has full control over all tags that need consent, Autoblock may be for you.
Conclusion
I am not saying no one should use Autoblock. It has its uses. Just make the decision with a full understanding of the implications, and an awareness of what other options may look like.
I’m curious to hear other’s thoughts and experiences.
I spend way too much time on a daily basis waiting for Launch libraries to build- on particularly bloated libraries, I’ve had it take up to two minutes. And, with my ADHD, I get too easily distracted during that wait time. It’s a major productivity killer.
So I figured out I can throw this code in as a Live Expression in my Chrome Console:
And it chimes when the loading icon stops spinning.
I got the sound file from soundbible– you could replace it with whatever you want. Originally I had it pull from a sound that already exists on any mac (as found on stack overflow) but it made the script ugly and long.
If it isn’t working for you, double check which frame your Live Expression is trying to be on. For me, it automatically went to the “Main Content” frame, which is where it works best, but it sounds like for some folks, you may need to manually select it:
There are better ways to do this. I know this. If I had more hours in the day, I could even make a decent Chrome extension out of it. But this works for now, and I’ve already held on to this for months without blogging it, waiting for time to make it cooler, and it would appear that time is never going to come, so… here’s my imperfect solution.
Consider this a beta. I fully expect something about it will not work in some situation. Please let me know how it goes for you. Or if anyone wants to take it and improve upon it, I’d appreciate it!
Disclaimer: I’m not a lawyer. Please don’t take any of this post as legal advice. I claim no responsibility for how the information in this post is used. Each organization needs to work with their lawyers to ensure their setup is compliant. Please test thoroughly and often to make sure your OneTrust set up is working as expected.
You’ll note I’m not calling this “The Best Way to set up OneTrust in Launch”, because I don’t know if this IS the best way; it’s just the only way I could get it all to work in my particular situation. If folks have found other potentially better ways I’d love to exchange knowledge! I will be updating this post if and/or when I learn new things.
To be honest, this is one of the scarier posts I’ve written (and not just for legal reasons)- I fully expect someone to say “this is a really weird way of doing it” (heaven knows I’ve said to myself “there must be a better way”). And I do know there are probably a few places where I could simplify/optimize. But I’ve talked to a lot of different people trying to set up OneTrust, and no one has ever been able to give me a different/better way yet, and I’m getting asked weekly how I’ve managed to get it to work, so here goes!
While this post is very specific to Adobe Launch*, a lot of the script and logic could apply to any TMS/Adobe Analytics setup. Some of it could even apply to other Consent Management Platforms (CMPs).
This post is long, and while the topic is complicated, much of what I’ve included is just for reference, so please don’t feel overwhelmed. We’ve got this.
Also, don’t be evil. I primarily work with first-party analytics (ie, Adobe Analytics), and I have no ethical compunctions about doing so. The only impact we have on the user is we improve website experiences (and I don’t mean that in a “we show better ads” way… I mean our focus is the actual site user experience). That said, I don’t want to “trick” the user into allowing it, and I want them to be informed about it. But consent management (and tag management) also applies to stuff that can be very ethically (not to mention legally) questionable. Prioritize your user’s privacy. Keep them informed. Remember most regulations don’t care specifically about cookies, they care about what you are doing with user’s data (which often includes but is not limited to cookies). There is no “getting around” requests for privacy. (That goes for server-side tracking, too, by the way.)
My Goals With This Setup (Opt-In and Opt-Out)
I’ve worked with OneTrust*** and Launch a fair amount, but for one project in particular, I had nearly complete ownership of it- this is the project I’m basing this post off.
Their set up had to work for a Launch property that has users throughout the US, as well as in a few EU countries, meaning we need to account for situations where we can track only if the user has opted in (GDPR), AND situations where we can track until the user has opted out (most non-GDPR regulations, like California’s CCPA**).
We’ve set up two OneTrust templates and two Geolocation rules. Fortunately, OneTrust uses geolocation to tell which banner they need to show the user, and whether they should be considered opted-in or opted-out by default. Unfortunately, on the very first page view, if OneTrust hasn’t had a full chance to run its script and define those categories, you can have timing issues, so we’ll have to work around that in this solution.
Some organizations choose to just treat EVERYONE as opt-in-only, including in the US where that is not legally necessary. This definitely is the legally safest choice but given that most orgs get opt-in rates of 30-50%, you may end up losing 50-70% of your data. I’ve seen one site in the UK that only had 11% of users opt in, though if you optimize your banner and really think through how you present information to your users, you should be able to get it much much higher. Either way, our goal here was to opt-in as many people as we legally/ethically could.
OneTrust Setup
I’m not going to get too into too much detail here about the actual configuration in OneTrust; OneTrust’s documentation is pretty thorough (though guilty of the atrocity of requiring you to login to access it***) and this post is more than long enough already. This whole post assumes you have an entirely correct and compliant set up in OneTrust including that you’ve correctly created your “Categorizations”, you’ve created banners (though I do have tips for working with their CSS- ping me on twitter or slack if it’s giving you trouble), and you’ve made sure your Geolocation rules are set up correctly (make sure you check the “Do Not Track” and “Global Privacy Control” options!)
Don’t use Autoblock if you can help it
As you publish a script in OneTrust, it gives you an option to toggle on Automatic Blocking of Cookies, also known as Autoblock:
Autoblock basically allows itself to become a middle man between your user and anything your site is trying to load. Everything gets routed through it and it gets to choose which requests to block or allow, based on what the user has consented to. This may be tempting… in theory, you could leave all of your tags and cookies in OneTrust’s hands and not have to worry about setting up conditions in your TMS. (I’ve heard a few people mention how much this feels like when TMSes were touted as “one simple line of code that does all the work for you!”)
But please consider it only as a last resort! Yes, turning off Autoblock and instead using conditions to decide which tags to fire looks like a lot more work, but it’s more flexible, and gives you more control and visibility. (And, to be honest, getting Autoblock to work the way you want may end up being more work than you expect, anyways.) I had a whole section of this post devoted to Autoblock, but it was enough it merited a post of its own. So please, before deciding to use Autoblock, get enough information to make an informed decision.
Why not use OneTrust to block Launch altogether?
This is another kind of lazy (or overzealous) solution I’ve seen folks try: just don’t load your TMS library at all until the user has consented to some tracking. Certainly, it is a fairly safe approach (assuming you don’t have anything on your site, outside of your TMS, that needs consent). It really limits your flexibility, though. Especially if you have different categories for consent, you may want to fire analytics (performance category) but not Doubleclick (marketing/targeting category). Or you may have script in your TMS that doesn’t require consent… for instance, I know of one site that uses Launch to deploy some ADA compliance updates (hardly a best practice, but it happens). Or your TMS may have code in it that helps keep you compliant by managing cookies, etc.
In an opt-out scenario, such an approach seems a bit silly- by the time they opt out, your TMS has already loaded and may continue tracking link clicks, etc.
In an opt-in/GDPR scenario, there is a key reason I don’t like this approach: the ECID Opt-In Service, when set up properly, is very good at holding on to tracking until there is consent.
So if my page loads, and we don’t have consent, but my Page Load rule normally would have set variables and fire a beacon… those actions get queued up, so to speak, for once the user DOES consent. Once they click the “allow all” button, my Page Load rule doesn’t re-run, but the things it would have done initially, like sending page view data to Adobe, finally get to fire. That way, you don’t have to either fire a new rule after acceptance, or wait until the next page view, to get information about that first critical page view (which often includes things like Campaign tracking codes or session referrer information).
Why not use the OneTrust Launch Extension?
I hate to say it, but the OneTrust extension doesn’t offer many advantages***. There is still enough you have to set up and tweak outside of it that in the end, you may as well just skip using it. Not using it keeps everything transparent, too, which I like.
Global “True” Page Top Rule
The setup we used needed a rule that runs before anything else possibly even starts. This is particularly important if you are firing your OneTrust library from within Launch, but you may want it either way, to set up compliance logic before anything else fires.
We didn’t even use “Page Top” as the trigger; rather we used a little trick that ensures it really is the first thing to run: we create an Custom Code Event that just contains one line of code:
trigger();
And we set the order on that to -1 (or 0 or 1… just make sure it’s a lower number than anything else):
That may all seem overkill (and it may very well be) but it gives us some peace of mind, without negative side effects.
Inserting the OneTrust library (from within Launch, if you must)
Ideally you would have your devs insert the OneTrust library directly on the page, as high on the page as possible. This will give you the best chance to not have timing issues. To be clear: this is my recommendation. If you’re going that route, skip to the “Set up consent data elements” section.
But we live in the real world, where sometimes we have to work with what’s available. In this particular client case, a hard-coded reference to OneTrust wasn’t a practical option at the time, so we needed to add our OneTrust libraries into the Page Top rule we just created.
We put a single Custom Code Action in this rule, which calls on our OneTrust library. You can get these code snippets from within OneTrust- the important part is the data-domain-script. Note, you can get both a test script and a production script snippet from OneTrust, similar to how Launch has a dev environment to test your changes before you go to prod. Just make sure you’re using the right one for the stage you’re at.
We’ll also use this rule and code block to fire our Adobe/ECID consent, but we’ll come back to that later.
Set up consent data elements
I tend to have one master “Onetrust Consent Groups” data element, then data elements for each category:
For the master consent groups data element, we have a few things we need to consider. OneTrust provides two places to see what groups your user is in:
1. The most supported-by-OneTrust approach is to use a Javascript object, window.OnetrustActiveGroups, which returns a value like this: ‘,C0001,C0003,C0007,C0004,C0002,’ These codes correspond to the Categories you set up in OneTrust. You can view YOUR Categories by going to Categorizations>Categories.
2. An “OptanonConsent” cookie, which I’m pretty sure they don’t particularly want us using, but it can be handy because once it is created, it’s accessible as a page loads, before that window.OnetrustActiveGroups object is. It returns a value like this:
…which is a bit messy, but potentially useable. I don’t currently use it in my solution but I figured I’d note it because I have seen others use it.
Important: Timing Issues for opt-in land (GDPR)
(To be clear, much of this section is only needed for folks who have timing issues because their OneTrust library is loaded by Launch or isn’t loading before Launch starts trying to do stuff.)
The problem is, if your OneTrust library is not called as high on the page as possible, there is a chance that OnetrustActiveGroups JavaScript object won’t exist when you need it; on each page load, it has to wait for the OneTrust library to create it. And the cookie only exists after the first time the OneTrust library loads… meaning if it’s the user’s first page view, you won’t know whether they count as opted-in or opted-out until after the OneTrust library loads! That’s one reason you should put the OneTrust library as high on your page as possible. But if you can’t, or you just want a failsafe, you can define some default consent groups. This would be simple if you were in a everyone-is-auto-opted-in scenario, or a everyone-is-auto-opted-out scenario. Where it gets fun is when you need to account for both.
Fortunately, my client already has a reliable method to tell me the user’s country (and even continent!) I’ll be honest, I’m not sure what I would have done otherwise, because we have to be able to detect the user’s jurisdiction to decide if they should be auto-opted-in or auto-opted-out. I have some theories of other ways we could do this but I’m glad I already had a reliable way to do it. Here is what I did for my “onetrust consent groups” data element:
try {
var consentGroups=""
if(window.OnetrustActiveGroups){
consentGroups=window.OnetrustActiveGroups //if this exists and is accurate, use it. We often have a timing issue though. So, our back up options:
}else if( _satellite.cookie.get("OptConsentGroups")){
consentGroups=_satellite.cookie.get("OptConsentGroups") //if we've previously gotten the consent groups, we don't have to worry about the timing with onetrust, we just grab it from a cookie that we create
}else if(_satellite.getVar("continentCode")=="eu" || navigator.globalPrivacyControl==1 || navigator.doNotTrack==1){//if no previous permissions, but in the EU or have GPC or DNT enabled, opt OUT of all not-strictly-necessary
consentGroups=',C0001,'
}else{ //everyone NOT in the EU who doesn't have GPC or DNT gets auto-opted-in to all categories
consentGroups=',C0003,C0001,C0007,C0004,C0002,'
}
//store groups in a cookie
_satellite.cookie.set("OptConsentGroups", consentGroups, {expires: 360, samesite:"lax", secure:true, domain: "example.com"})
return consentGroups;
} catch (e) {
_satellite.logger.info("onetrust error:" + e);
}
Basically, if OneTrust has loaded, great, let’s use their JS object. If not, then based on the user’s location or privacy settings, we auto-opt them in or out of all categories (aside from “strictly necessary”). Then we create our OWN cookie, OptConsentGroups, so it’ll be easily accessible early on in the next page load.
NOTE: YOUR CATEGORIES WILL VARY. C0002 is for performance cookies for this particular client, based on how they have their categories set up within OneTrust. You will need to figure out how to identify the categories for your set up.
This data element gets referenced in a few places, meaning it is constantly getting updated, in case preferences change.
Set up data elements for each category
Once that data element exists, I create data elements for each category. My “onetrust consent: marketing” data element looks like this:
I’ll use these to create conditions for any of my rules that contain non-Adobe tracking. Adobe rules don’t need conditions, they’re handled by the Experience Cloud Opt-in service.
Set up the ECID Opt-in Service
This is how I configured the Experience Cloud ID Service extension, essentially shifting all the work to my “onetrust consent: adobe” data element:
That “onetrust consent: adobe” data element looks like this:
var consentGroups=_satellite.getVar("onetrust consent groups")
var consent=false //false by default
//set per adobe category (we're treating all three- analytics, ecid and target- as performance. Your situation may merit a different split)
if(consentGroups.indexOf("C0002")!=-1){ //C0002= performance cookies
var consent=true
}
//_satellite.logger.info("onetrust consent groups:" + consentGroups) //handy for debugging
return { aa: consent, target: consent, ecid: consent };
It checks if the user has consented to “performance” tracking, and if so, returns an object like this:
{aa: true, target: true, ecid: true}
This is the format that that “previous permission”/pre-opt-in approvals piece of the ECID is looking for. I’d love to say I learned that in the Adobe Documentation, but unless I’m missing something obvious, you have to backwards-engineer their code example to figure it out. Fortunately, this blog post by Abhinav Puri documents it all nicely.
(But wait, shouldn’t Adobe Target be categorized as “Targeting”? You should definitely ask your lawyers, but by my reasoning, the Targeting category is for targeted advertising and retargeting. Adobe Target may be named Target, but it is primarily a user experience/performance tool. It doesn’t chase you around the internet with personally-relevant advertising.)
Setting up the extension with this data element will cover Adobe permissions on page load, before the user interacts with the banner.
(In theory, this ECID extension part is the main thing the OneTrust extension would help with. But I like keeping all of the logic very transparent. And I’m a control freak that doesn’t trust vendor code I haven’t thoroughly tested.)
Updating Permissions (Banner Interaction)
To update permissions when the user has changed their preferences (including their initial reaction to the banner), I added code to my Page Top rule, within the OptanonWrapper() function, which is functionality provided by OneTrust that fires when OneTrust library first loads, as well as whenever there is a change to the user’s permissions:
<script type="text/javascript">
function OptanonWrapper() { //this function runs any time there are changes to one trust
var consentSettings=_satellite.getVar("onetrust consent: adobe")
if(consentSettings.ecid===true){ //experience cloud ID service
adobe.optIn.approve('ecid',true);
}else{adobe.optIn.deny('ecid',true);}
if(consentSettings.aa===true){ //analytics
adobe.optIn.approve('aa',true);
}else{adobe.optIn.deny('aa',true);}
if(consentSettings.target===true){ //target, obv
adobe.optIn.approve('target',true);
}else{adobe.optIn.deny('target',true);}
adobe.optIn.complete();
}
</script>
(In theory I could simplify this a bit since all three categories pretty much always have the same consent, but I wanted this to be flexible for potential changes in the future.) So now that rule looks like this:
(If you’re not deploying your OneTrust Library through Launch, then lines 1-7 don’t apply.)
Set up Rule Conditions
Fortunately, the ECID Opt-in Service will handle everything Adobe-related: you do NOT need to take further action, such as adding Rule Conditions to all rules with Analytics actions, in order for Analytics to not fire when it shouldn’t. The rules will still fire but they will not send anything to Analytics or Target (yet).
Marketing tags, however, need to be explicitly told to pay attention to the user’s consent preferences. This is, unfortunately, still a very manual process. First, you may need to make your rules a little more category-based. In general it’s easiest if for any particular rule event/condition combo, if you have your performance-category actions together in one rule, and your marketing/targeting actions in a separate rule. We were already generally following that, but there were a few rules that had both analytics and marketing tags- for those, I copied the rule and deleted analytics out of one of them and deleted the marketing tags out of the other one, resulting in one analytics-only rule and one marketing-tag-only rule. The analytics-only rule is fine as-is (thanks, ECID!) but the marketing tag rule needs an extra condition.
If your entire rule falls into one consent category, then it’s as simple as adding a condition where “%onetrust consent: marketing%” equals “true”:
If, however, you need to use conditions within your code to decide what fires and what doesn’t (perhaps your rules don’t neatly align with your categories), that might look like this:
if(_satellite.getVar("onetrust consent: marketing")=="true"){
//insert code for marketing tag here
}
If someone out there has some extra time on their hands and wanted to write a Launch API function that would automatically add such a condition to all rules, that sure would be swell. In the meantime, I tend to take this approach: open my list of rules, and starting at the top, left-click on each rule while holding down cmd (or ctrl for a PC). This will open each rule in a new tab, while leaving your Rule List tab alone so you can keep track of what you’ve done and not done.
Then work you way through the tabs, adding your condition, saving, then closing that tab. I’ll often open 10-15 at a time, being careful to note where in the rule list I stop. When you’re done, you can use something like Tagtician to export your whole library and make sure you didn’t miss anything.
Side Note: Don’t forget to honor non-banner-based opt-outs!
Part of the California Consumer Privacy Act (CCPA) and others like it, is that sites must have a “Do Not Sell My Personal Info” page where the user can opt out, or view/delete/modify what data you have on them. Lawyers have generally been pretty good about making sure orgs get these pages in place- you probably already have one. Often, these pages are set up to sync up with the org’s CRM… if r.swanson@pawnee.gov fills out a form to opt out of tracking, then the CRM may delete all the info they have for dear R.Swanson, and/or someone may use the Adobe Privacy API or the Adobe Privacy JS to delete/edit/modify/view the Adobe data on that user. That’s all as it should be. The problem is, this process often exists completely separately from the Consent Management Platform. You may have deleted the person for your backend systems, but you’re still setting cookies and collecting data on the site!
Make sure that your Tag Manager knows when these kind of opt-outs occurs and honors them. OneTrust does have a way of tapping into those forms, though I can’t find any public documentation other than this general good advice about CCPA. But within their knowledge base, look up “Do Not Sell for AdTech Vendors”- it has tips and script you can use to help OneTrust know what happens on those forms.
Side note: Cookie Deletion
Note, right now, when you tell the ECID Opt-in Service to opt a user out of tracking, it does not remove any existing cookies. So in an opt-out situation, where everyone gets cookies to begin with, you may have users that have declined tracking and won’t be getting analytics beacons, but still have Adobe-created-cookies in their browser. Legally, this is a bit of a gray area. Even if it is technically legal (I’ll leave that to the lawyers to confirm), unfortunately the general public cares a lot about appearances. I’ve already seen one instance where Adobe cookies that were set but not even used (the site didn’t fire analytics beacons) caused a lawsuit in Spain, where they were accused of being “one of the most invasive types of cookie for user privacy”. This is complete nonsense, but the authorities and all the lawyers involved may not understand that without a bunch of effort. Even if the lawsuit fails, it has consumed a lot of that company’s resources.
At bare minimum, you should consider adding verbage to your banner or privacy policy that instructs users how to delete cookies on their own. The regulations strongly encourage this.
If you want to delete the AMCV and AMCVS cookies on behalf of the user, it can be a little tricky, since most of the time there is a domain mismatch between the www.example.com site you are on and the “.example.com” domain the AMCV cookies are set at, so you can’t just use _satellite.cookie.remove or somesuch. But you can do something like this to delete them:
Note, many plugins also create cookies- you might see s_ppv or s_vnum or any number of other “s_” cookies that are the default names of cookies created by Adobe plugins. Generally, these don’t have “personal information” and in theory shouldn’t have to worry too much about (though I am not a lawyer so please don’t base your decisions off of me), you may want to delete them or at least be aware of them.
Depending on your ECID settings, you may also be setting a demdex cookie. Since this is a third-party cookie (and can effect how users are identified on other sites) it’s even more legally dodgy, and unfortunately even more difficult to delete. You can either stop that cookie from being set to begin with ECID’s disableThirdPartyCookies setting, or be very careful in how you inform your users about it and their ability to opt-out and/or delete it.
Validation
Here is a non-comprehensive list of things to check to confirm you have things set up correctly: obviously, you want to validate that your Analytics, Target, ECID, marketing tags, targeting tags, etc all only fire with user consent. Check both for cookies (in the “Applications” tab if you’re in chrome) and beacons/scripts (in the “Network” tab). Double check that your setup honors the Global Privacy Control signal (I’ve found this easiest to do in Firefox). Check that the user experience isn’t hindered. Be careful to check things that may be using third party technology, like video players- both that they work, and that they comply with consent policies. If you have iframes anywhere on your site, make sure the content within them is also being controlled by your CMP. Make sure you test for each of your Geolocation rules in OneTrust.
Ideally, before you roll out major OneTrust changes, you’d do a full regression test (the type of QA typically done before a major site release, where you make sure none of your pre-existing stuff is impacted). If you are resorting to using Autoblock for anything, a full regression test is a necessity.
Things I’ve found useful for testing:
OneTrust does provide a preview mode, but the most important thing I got out of that is that you can use query parameters (even in production) to change how OneTrust behaves. This will pretend you are in Great Britain (which follows GDPR, but is not an EU country- you may need to add it separately in OneTrust):
?otreset=true&otpreview=false&otgeo=gb
Or California:
?otreset=true&otpreview=false&otgeo=us,ca
For example, the above combo resets my preferences so I’ll see the banner again (you can also do this by deleting the OptanonAlertBoxClosed cookie.) The handiest part is the otgeo param- I can have Onetrust treat me like I’m in Great Britain (or any other country code I put there) to test that it works as expected in different jurisdictions.
Another useful thing: you can use this in the console to see what Adobe thinks its current permissions are:
adobe.optIn.permissions
I console.logged the heck out of that when figuring out the timing of things.
Tracking Opt-In/Opt-Out Rates
This is a tricky subject: how do you track that someone said they don’t want to be tracked? It may be worth a chat with your lawyers about. It’s important to remember, most regulations are more about having personal information, such as an ID in a cookie (even anonymous IDs), sent to third parties. Cookies are generally needed for keeping track of a session/visitor from page view to page view (or domain to domain, in some cases). If you are only tracking one user action without context, and there is nothing that ties that action to a particular user in any way, then the user has far less to be concerned about when it comes to their privacy. It’s sensitive and definitely worth discussing with your lawyers, but most regulations do allow for the most basic of tracking if there are no IDs used, the data isn’t shared or sold, it’s stored and processed correctly, the user is informed, etc. The data is useless for journey analysis and attribution, but can actually be used to make sure you are respecting user’s privacy properly. But TALK TO LAWYERS before deciding on any such tracking.
OneTrust does have the option to get high-level reporting on consent rates. I would link to the documentation on it but I’ve never gotten a link to Onetrust documentation to work. Instead, I have to click the ? icon and read any documentation within that panel:
I’ll admit I have not enabled or used their reporting. I’m curious how they get the info they do in cases where the user has consent to zero tracking. I’m assuming that it is free of personal information such as a cookie ID, etc.
We implemented another solution, where for the first 2 weeks after launching OneTrust, we fired hard-coded, identifier-less/cookie-less Adobe Analytics beacons to a Report Suite set up for that purpose, just to get a rough estimate of how it was working. I hope to have a separate blog post about that in the near future.
Adobe Analytics Settings for Privacy
Adobe does offer some admin settings that also help with privacy. You may want to consider these in addition to what you have set up in your TMS:
Your General Report Suite Settings include a “Replace the last octet of IP addresses with 0” option and an “IP Obfuscation” option. The first happens before any processing on a hit, meaning the IP never gets stored or processed, and everywhere in Adobe, that user’s true IP is not accessible (including Data Warehouse and Data feeds). Accordingly, it has an impact on your reporting, especially geolocation rules. The IP Obfuscation Option, on the other hand, happens after some processing is done, so it has less impact. You can use it to merely obfuscate, or to remove the IP address altogether.
I only just learned of this back-end setting that respects browser privacy settings (presumably, the older Do Not Track option or the newer Global Privacy Control setting). In theory, if your OneTrust/TMS implementation is configured right, nothing with those flags will ever even make it to Adobe, but there’s no harm in a little redundancy, right?
Conclusion
As I said at the beginning, I would love to learn more and improve my approach where possible. The best solution may end up being a crowd-sourced one. Please let me know what has worked or not worked for you!
* Sorry, Adobe. No one is going to convince me to call it “Data Collection Tags”.
** CCPA: I know there are many laws out there beyond California’s Consumer Privacy Act; however, since CCPA tends to be one the most expansive laws ( for now), I tend to use the phrase “CCPA” as an umbrella stand-in term for US laws. It’s much more complicated than that, but I don’t want to open that can of worms every time I need to reference a opt-out-based regulation.
*** If it wasn’t clear, this post was not done in partnership with OneTrust, and I have no formal relationship with them. I’d be happy to talk to them about anything in this post, though. And for what it is worth, of the 5 CMPs I’ve worked with, OneTrust was the least awful, in my experience.
How you name your rules, events/triggers, tags and actions can have a big impact on the health of your TMS. You want to prevent duplicated conditions and logic as much as possible, to keep things simple, lighter, and less error-prone. You want to make things easier to find and easier to put into context.
Launch Rules, Events, Conditions, Data Elements, and ACTIONS
Let’s face it, the internal search functionality in Launch isn’t great. But there is much you can do to make navigation within Launch easier and cut down on duplicated logic.
For rule names, I often follow a format with some combination of the following:
category[: sub category] | trigger | [type (analytics or marketing)] | what the rule does/marketing vendor | load order | consent management category
For example:
add to basket | “add to basket” event | analytics | s.tl | #50 | C0008
search: search results | “page view” event | analytics | set vars | #50 | C0008
Of course, it usually differs for every client depending on their needs. For me, the important thing is for rules with similar events/conditions to be together (all my search rules start with “search:”), to know what triggers it (page bottom? direct call rule?), and to have an idea of what’s inside. Here’s a simpler version:
Having it arranged this way already shows me for this property…. I have a lot of rules firing on that page view event. I could probably consolidate some of those into a single rule. I also see some inconsistency… one “page view” is lacking quotes, which makes the editor in me twitch a bit, and in that top one I didn’t specify s.t or s.tl beacon. But you know what? I can navigate this property pretty easily. And if I see an inconsistency, I can fix it as I go along. Some order is better than none.
Sometimes I only include the event order (eg, #50) if it’s something other than the default of 50. Sometimes we have analytics and marketing in the same rules so the standard has to adapt.
For events, I only change the name from the default if I had to customize it- page bottom is always just “Core – Page Bottom” (unless I changed the order, in which case I’d probably name it “Core – Page Bottom #1” or somesuch), but a direct call rule or something based on a CSS selector should always include that info in the name. For instance “click on .pdf links”, “DCR page view #25” or “payment modal enters viewport”. I won’t even be picky about following a standard… just keep it informative. If you changed the order (from #50 to, say, #1), then do note that. It makes troubleshooting so much easier.
Conditions should always have custom names. “Core – Value Comparison” is just not helpful… but “pageType of ‘search results'” is. Again, I’m not picky about following a standard… just make it so I don’t have to click into the condition to have an idea of what it is.
Action naming… this is where I get excited. Folks don’t take advantage of Action names nearly enough. Action names should include the marketing tag name and the scope. Within a rule, it might look redundant with the rule name (how many times do you see “All pages/Page Top” here) :
But if you search for a tag in the Launch’s search tool, those action names make a world of difference. Let’s say I’m searching for eVar63… this:
…is not helpful (by the way, please go upvote this feature request for better search functionality). I’d have to click in to each of those to find out what the context is to know which one I want to make my change to. But if I’ve added a bit of information to the action name, I can know exactly where it is taking me:
It’s a minor inconvenience when setting rules up, but if you have a complex implementation, it can make life so much easier.
For data elements, I tend to go much simpler. Some sort of categorization, then some sort of detail. If it suits the implementation, I might add more information about the source of the data. For example:
search: term | QP
search: number of results | DL
marketing: cmpid
content id: page name
I tend to always keep it lower case, since you have to have to right case when referencing a data element.
Don’t stop with good names, add even more info!
As I mentioned in my post on governance, it can be extremely helpful to include information about the tag within the tag itself, along these lines: