I’m speaking at the Marketing Analytics Summit about marTech tracking and how to keep tags from causing problems on your site. In true Jenn fashion, I have way more that I want to convey than I can possibly cram into my 30-minute presentation, so I have a series of blog posts to store all the practical takeaways:
A free excel download that shows you how to easily export information about domains on your site from webpagetest.org, then analyzes those domains to show you their impact on your site.
If there is one thing I hope folks take from my presentation, it’s to do something now. You don’t have to wait until you have a ton of resources to do a full audit and clean up. Do what you can, when you can. Implement standards for tagging going forward. Even if it only helps a few tags, your future self will thank you.
If you’re here in Vegas for the Marketing Analytics Summit this week, let me know, I’d love to meet up!
I’m presenting as part of a Rockstar Tips & Tricks session at Adobe’s Virtual Summit this year- if you’re registered, you’ll eventually able to view the recordings on-demand. But in case folks miss it or want more detail, this post walks though the tips/tricks I’m presenting. With the old Reports & Analytics (R&A) reports going away, I want to look at some of the cool fallout and pathing things we can still do in workspace.
Note, I do think this will all make more sense in a video demo than in a blog post, but I know the presentation went pretty fast, so this post can be a sort of supplemental guide for the video demo.
TL;DR
If you’re coming from my presentation and just want that way under-used TEXTJOIN excel formula from the end of Tip #2, here you go:
=TEXTJOIN(">",TRUE,A13:E13)
Also, in case I didn’t make it clear in my presentation (I didn’t), I recommend this Pivot Table filter to get to Full Paths: descending, by “Sum of Path views”, filtering on “Complete Path contains Exits”.
If that makes no sense to you, or you just want the full context, read on:
Tip #1: Fallout and Funnels
In the old R&A days, I had a few ways to track a conversion flow fallout:
The Custom Events Funnel gave a nice little graphical interface to compare numbers in. You could drag in events (no dimensions) to see them in a funnel.
A few things to note, though: first, the graphic did not change based on the data, so it could be misleading. Second, it didn’t actually pay attention to if the user did the events in sequence (notice in my screenshot that I have zero checkouts because I forgot to set it, yet 60 orders). Really, it was just a way to compare difference between events, regardless of sequence.
There was also a fallout report in R&A, which could be built off of pageName or any prop that you had the foresight to have pathing enabled on. (At least its graphic matches the data.)
Both of these are replaced in Workspace by the Flow visualization, which can be used for events (like an old Events Funnel):
Or on page names (or any other dimension- not restricted to pathing props):
This is already showing more flexibility and power than the old R&A pathing reports. But you could also mix and match events and dimensions. Let’s say I have a new campaign with 4 marketing landing pages and I want to see how those 4 pages collectively affect my Fallout. Because I’m setting page type in an eVar (which I consider essential to any implementation), I can bring in the page type to represent all four of those pages together, then continue the funnel based on page name:
I could pull events, props, and eVars all into the same report and see them in sequence and the fallout between. But I can take that a step farther and drop dimensions and segments into the area below the visualization key , where it that currently says “all visitors”, to compare how the fallout looks for just that dimension or segment. For instance, if I now want to compare those four pages, I can:
(Note, the top step has 100% for each dimension value because of course 100% of the visits with that page type have that page type.)
This visualization helps me spot something pretty immediately: the marketing page represented by the purple (sorry the names get cut off in the screenshot so you can’t see my Harry Potter references) got by far the most visits (75), but had the worst fallout. Whereas the one in pink had far viewer visits but much better retention. I’d probably go to the marketing or content team and see if we could get the best of both worlds somehow: whatever we’re doing to GET people to the purple marketing page, plus whatever content is on the pink one that seems to be getting people to STAY.
That’s just one made-up example, but there are so many ways this could be used. Let me know if you’ve found other fun ways.
Tip #2: Full Path Report and the Flow Visualization
One thing that Reports and Analytics for which Workspace doesn’t have a direct equivalent are the Full Path and Pathfinder reports. The Full Path report would show, well, the most popular full paths that users took through the site, from entry to exit:
Personally, I didn’t see a ton of value in this report because it would be so granular… if one visitor went page a>b>c>d, and another did just b>c>d, and another just a>b>c, they’d all appear as different line items in the report. However, I do know some folks like to include this in dashboards and such. But in my mind, most of the insight/analysis would be done in a Path Finder report. This helpful little tool would let you specify certain flows and patterns you were interested in, leaving room for filling in the blanks. The Bookends Pattern was a particular favorite: what happened between point A and point B? This would help analysts see unexpected user paths.
This is the functionality that currently workspace can’t directly replace. The closest we get is a flow visualization…. which may very well be my favorite Workspace tool. I should write another post about all the lesser-known great things about this report (segments! trends! pretty-and-useful colors!), but for now I’m going to focus on turning it into a full path report.
First, I bring Page in as an entry dimension. At this point, it should just be showing me my top entry pages. Since I want a more complete story, I’m going to click the “+_ more” so it includes more pages, then I’m going to right-click on that column and tell it to “Expand Entire Column”:
That’ll add a second column. I’ll keep repeating this process until I have 5 or 6 columns as expanded as can be.
Unfortunately, you probably don’t want to expand columns too deep or too far to the right because after a while Workspace starts slowing down and struggling. So this won’t cover all paths but it will help us get the most common ones.
With all of the winding and webbing between pages, it’s still hard to get at that list of paths…. for that, I need to take the report to Excel. So I send the report to myself as a CSV (either through Project>Download CSV, or Share>Send File Now). This gives me something like this:
It’s not quite useful yet. And something kinda odd happens, where it shows me all possible combinations of paths, even ones that never happened (all the lines that don’t have a number in the “Path views” column.) But that’s ok, we can ignore those for now. What I am going to do is create a new column to the right, and put this formula in it:
=TEXTJOIN(">",TRUE,A13:E13)
(Where A13:E13 are the cells of that row that contain all of my steps).
Then I copy that formula all the way down. This gives me a single string with complete paths, like “Entry (Page)>home>internal search>product details:skiving snackboxes>checkout:view cart>Exits”. I’ll also throw a name at the top of that column like “Complete Paths”.
This still isn’t really great for analysis, so I take it one step farther, and create a pivot table by selecting all the cells in my “Path Views” and “Complete Paths” columns (except for the empty ones up top), then going to the “Insert” tab in excel and clicking “Pivot Table”:
This will create a new sheet with an empty pivot table. I’ll set up my Pivot Table Fields with “Complete Paths” as my rows and “Sum of Path Views” as my values:
Then I’ll sort it, descending, by “Sum of Path views”, filtering on “Complete Path contains Exits” (otherwise you get incomplete portions of journeys, as the download will show the path “entry>a>b>c>exit” as “entry>a”, “entry>a>b”, “entry>a>b>c”, and “entry>a>b>c>exit”).
And there we go! A very rough approximation of Full Paths.
But there are a some nuances and caveats here, the main one being that it only goes so deep. The Flow Visualization really starts struggling when you have too many fully expanded columns, and the downloaded CSV reflects only the number of columns you had in the visualization. So paths that are longer than than the 4-6 columns are going to be excluded. Accordingly, this is ideally used for most common paths (which usually aren’t more than 5 or 6 pages anyway).
So this shows Full Paths, but where does that Path Finder stuff come in? Really, I’d expect this to serve as a starting point for a lot of further analysis in excel, where you can use filters to find the paths that interest you most (eg “begins with” or “ends with”). Hopefully before R&A goes away, Adobe will have some way to truly replicate that Path Finder functionality, but in the meantime, this at lease gives you some options. If you have a specific use case you want to achieve and don’t know how, leave a comment here or find me on #measure slack or twitter, and I’d love to help you figure it out.
If nothing else, now more of the world will know about how handy TEXTJOIN is ;).
This is a bit anticlimactic of a post, for my triumphant return after a long while of not blogging, but this question keeps coming up so I figured I’d document it publicly so I can reference it when needed. I find many of my posts that are for my own benefit, to use as a reference, tend to be the most viewed posts, so here’s Jenn’s notes to herself about converting Doubleclick tags to gtag:
Quick Reference
If you’re generally familiar with gtag and the old Doubleclick/Floodlight/Search Ads 360 tags, and just want a quick reminder of the order of things, here is the format of the send_to variable, inspired by Google’s documentation:
‘send_to’ : ‘DC-[floodlightConfigID (src)]/[activityGroupTagString (type)]/[activityTagString (cat)]+[countingMethod-either conversion or purchase]
That’s src, type, and cat pulled from these spots:
If that doesn’t make a lot of sense to you, you need more examples, or you just want to understand it better, read on.
Walkthrough
Doubleclick’s standard tag used to look something like this (sometimes using an img instead of an iframe, but the same general idea either way):
<!--
Start of Floodlight Tag: Please do not remove
Activity name of this tag: Jenn-Kunz-Example-Tag
URL of the webpage where the tag is expected to be placed: https://www.digitaldatatactics.com/
This tag must be placed between the <body> and </body> tags, as close as possible to the opening tag.
Creation Date: 08/18/2021
-->
<script type="text/javascript">
var axel = Math.random() + "";
var a = axel * 10000000000000;
document.write('<iframe src="https://12345678.fls.doubleclick.net/activityi;src=12345678;type=myagency;cat=jkunz_001;dc_lat=;dc_rdid=;tag_for_child_directed_treatment=;tfua=;npa=;gdpr=${GDPR};gdpr_consent=${GDPR_CONSENT_755};ord=' + a + '?" width="1" height="1" frameborder="0" style="display:none"></iframe>');
</script>
<noscript>
<iframe src="https://12345678.fls.doubleclick.net/activityi;src=12345678;type=myagency;cat=jkunz_001;dc_lat=;dc_rdid=;tag_for_child_directed_treatment=;tfua=;npa=;gdpr=${GDPR};gdpr_consent=${GDPR_CONSENT_755};ord=1?" width="1" height="1" frameborder="0" style="display:none"></iframe>
</noscript>
<!-- End of Floodlight Tag: Please do not remove -->
Some agencies/deployments still use this format. You may get a request from an agency or marketer to deploy a tag documented this way. But if you already use gtag on your site, or you just want to modernize and take advantage of gtag, you can convert these old iframe tags into gtag by just mapping a few values.
Before you get started, you need to note a few things from your original tag:
1. The “src”, also known as your account ID. 2. The “type”, also known as a “Activity Group Tag String” 3. The “category”, also known as the “Activity Tag String”
Keep track of these, we’ll use them in a moment. (If you also have custom dimensions or revenue and such, hang on, we’ll get to those in a bit.)
Step 1. Global Site Tag code
First, make sure you have gtag code on your site. No matter how many tags use it, you only need to reference it once.
Note, I’m only walking through the code; if you’re in Launch, using a tool like Acronym’s Google Site Tag extension (which is great, in my opinion), hopefully this post combined with their documentation will be enough to get you what you need to know.
<!--
Start of global snippet: Please do not remove
Place this snippet between the <head> and </head> tags on every page of your site.
-->
<!-- Global site tag (gtag.js) - Google Marketing Platform -->
<script async src="https://www.googletagmanager.com/gtag/js?id=DC-12345678"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'DC-12345678');
</script>
<!-- End of global snippet: Please do not remove -->
The part that matters, that establishes which gtag accounts you want to set up, is in the config:
This is where you’d put #1- Your Account ID. Add a “DC-” to the front of it (DC for Doubleclick, as opposed to AW for AdWords…), and you have your config ID.
Step 2. Send an event
With that, you have the gtag library on your page, and you’ve configured it. But this merely “primes” your tracking…. it sets it up, but does not actually send the information you want. For that, you need to convert your original iframey tag into a gtag event. A traditional gtag event looks like this:
<!--
Event snippet for Jenn-Kunz-Example-Tag-Home-Page on https://www.digitaldatatactics.com: Please do not remove.
Place this snippet on pages with events that you’re tracking.
Creation date: 08/19/2021
-->
<script>
gtag('event', 'conversion', {
'allow_custom_scripts': true,
'send_to': 'DC-12345678/myagency/jkunz_001+standard'
});
</script>
<noscript>
<img src=""https://ad.doubleclick.net/ddm/activity/src=12345678;type=myagency;cat=jkunz_001;dc_lat=;dc_rdid=;tag_for_child_directed_treatment=;tfua=;npa=;gdpr=${GDPR};gdpr_consent=${GDPR_CONSENT_755};ord=1?"" width=""1"" height=""1"" alt=""""/>
</noscript>
<!-- End of event snippet: Please do not remove -->
But the part we need (and the only part that actually sends info to google) is just this:
So this in your original iFrame/pixel Doubleclick tag:
Becomes this for gtag:
There are two other things to pay attention to in that gtag event, and they don’t map directly to something in your original tag:
(Note, the “allow_custom_scripts” will always be true, so you don’t need to worry about it.)
The event type (“conversion”) and the counting method (“+standard”) will reflect whether or not your tag is for a purchase or not. For the Counting Method, Google says:
Standard counts every conversion by every user. This is the counting method for action activities generated in Search Ads 360.
Transactions counts the number of transactions that take place, and the cost of each transaction. For example, if a user visits your website and buys five books for a total of €100, one conversion is recorded with that monetary value. This is the counting method for transaction activities generated in Search Ads 360.
Unique counts the first conversion for each unique user during each 24-hour day, from midnight to midnight, Eastern Time (US).
In other words, most cases will be “conversion”/”+standard”, unless you’re tracking a purchase, in which case it will be “purchase”/”+transaction”. If your original tag has cost and qty in it, then it’s a purchase, otherwise, it’s likely just a conversion and you can use “+standard” as your counting method. On a rare occasion, you may be asked to use “+unique” so the conversion only counts once per day. I hear there may be other counting methods, but I don’t have examples of them.
If your tag is a conversion and you’re not sending custom variables, then the allow_custom_scripts and the send_to is all you need- you’re done! If it is a transaction and/or you have custom variables, read on.
Transactions
If your original iframey tag is intended for a purchase confirmation page, it probably includes a “qty”, “cost” and “ord”, with the intent for you to dynamically fill these in based on the user’s transaction:
If so, then your gtag will need a few more things, like value and transaction_id (and make sure your event type is “purchase” instead of “conversion”) :
The mapping for these is probably fairly obvious. What was “cost” goes into “value”; what was “ord” goes into “transaction_id”:
Quantity seems to have fallen by the wayside; the old iframey tags asked for it but I’ve never seen it in a gtag purchase tag.
Maybe it could go without saying, but to be clear, the expectation is that you’d dynamically fill in those values in square brackets. So if you’re in Launch, it might look like this:
Again, the expectation is that you would replace anything in square brackets with dynamic values that reflect the user’s experience. I often leave the description they provided in comments, just for reference and to make sure I’m putting stuff in the right places.
You may be wondering about some of the other bits of code in the original iframey tag:
The “axel” stuff was a cache buster, to prevent the browser from loading the iframe or img once, then pull it from cache for later views. The cache buster would generate a new random number on every page load, so to the browser it looked like a new file rather than the file it has in its cache. The good news is, gtag handles cache busting, as well as all that other stuff for you; it’s not needed any longer. Gtag also handles GDPR differently so you don’t need to carry those parameters over.
NoScript
A quick word about the noscript tags:
These are a remnant of an older internet, where mobile devices didn’t run JavaScript, and tag management systems didn’t exist. It says “if the user doesn’t run JavaScript, then run this HTML instead”, usually followed by a hard-coded pixel.
Frankly, it’s comical that anyone includes these anywhere anymore:
These days, the only devices not running JavaScript are bots. Unless you WANT inflated numbers (maybe some agencies/vendors do), you don’t want bot traffic.
Sometimes vendors/agencies will ask for dynamic values within the noscript tag: Which is just silly- without JavaScript, the only way to dynamically set those values would be to have them set serverside. Which I’ve never seen anyone do.
Finally… if you’re deploying it through a Tag Management System, and the user isn’t running JavaScript, the TMS won’t run at all, meaning the rule won’t fire, meaning the noscript tag will never get a chance to be written.
In short, delete noscript tags and their contents. Some agencies may not know these not-exactly-rocket-science nuances of the internet, and may whine at you about not including the noscript tag because they have a very specific checklist to follow. Include it if you must to appease the whiners, but… know that if it’s within a TMS, the contents of that noscript tag will never see the light of day.
How to send to multiple accounts
This isn’t tied directly to converting from old tags, but for reference…. if you want to send a gtag event to multiple accounts, instead of duplicating the tag, you can add a config in your global code:
<script async src="https://www.googletagmanager.com/gtag/js?id=DC-12345678"></script>
<script>
window.dataLayer = window.dataLayer || [];
function gtag(){dataLayer.push(arguments);}
gtag('js', new Date());
gtag('config', 'DC-12345678');
gtag('config', 'DC-87654321');
</script>
Then in your event code, turn the “send_to” into an array:
You may ask “If I only need to have the gtag library script once, and I have multiple gtags, what do I do about this id on the global script src?”
To be honest, that bit matters very little. I usually just delete it, or leave it with whatever ID was on the first gtag I added (if someone knows what purpose that ID serves and wants to tell me I shouldn’t be deleting it, please chime in). The “configs” are the important part.
Conclusion
It’s not exactly cutting-edge content, nor relaxing bedside reading, but I hope this comes in handy for those for those struggling to find answers in existing documentation. Cheers!
Disclaimer: I’m not a Doubleclick expert, but I have deployed many many Doubleclick tags- I daresay hundreds of them. If any of the above isn’t “gospel truth”, it’s “truth that worked for me”, but I’d love to hear if any of my reasoning/theories are incorrect or incomplete.
Almost every organization that uses Digital Analytics has some combination of the following documents:
Business Requirements Document
Solution Design Reference/Variable Map
Technical Specifications
Validation Specifications/QA Requirements
All of the consulting agencies use them and may even have their own special, unique versions of them. They’re often heavily branded and may be closely guarded. And it can be very difficult to find a template or example as a starting point.
In my 11 years as a consultant who focuses on Digital Analytics implementation, I’ve been through MANY documentation templates. I’ve used the (sometimes vigorously enforced) templates provided by whoever was my current employing agency; I’ve used client’s existing docs; I’ve created and recreated my own templates dozens of times. I’ve used Word documents, Google Sheets, txt/js documents, Confluence/Wiki pages, and (much to my chagrin) Powerpoint presentations (there’s nothing wrong with Powerpoint for presentations, but it really isn’t a technical documentation tool). I’ve in turn shared out templates and examples both within agencies and more broadly in the industry, and I’ve now decided it’s time to stop hoarding documentation templates and examples, and share them publicly in a git repo, starting with the most foundational: the Variable Map (sometimes called a Solution Design Reference, or SDR).
The Variable Map
You may or may not have a tech spec or a business requirements document, but I bet you have a document somewhere that lays out the mapping of your custom dimensions and metrics. Since Adobe Analytics has up to 250 custom eVars, 75 custom props, and up to 1000 custom events, it’s practically essential to have a variable map. In fact, the need for a quick reference is why I created the PocketSDR app a few years ago (shameless plug) so you could use your phone to check what a variable was used for or what its settings are. But when planning/maintaining an implementation, you need a global view of all your variables. This isn’t a new idea: Adobe’s documentation discusses it at a higher level, Chetan Gaikwad covered it on his blog more recently, Jason Call blogged about this back in 2016, Analytics Demystified walked through it in 2015, and even back in 2014, Numeric Analytics discussed the importance of an SDR. Yet if you want a template, example, or starting point, you still generally have to ask colleagues and friends to pass you one under the table, use one from a previous role/org, or you just start from scratch. This is why 33 Sticks is making a generic SDR publicly available on our git repo.
The cats out of the bag
There are various reasons folks (including me) haven’t done this in the past. For practitioners, there is (understandably) a hesitance to share what you are doing- you might not want your brand to be associated with how good/not good your documentation is, and/or you may not want to give your competitors any “help” (more on that in an upcoming podcast). For agencies, there may be a desire to not show “the man behind the curtain”, or they may believe (or at least want their clients to believe) that their documentation is special and unique.
So why am I sharing it?
Because I don’t think the format of my variable map is actually all that special- a variable map is a variable map (but that doesn’t mean we should all have to start from scratch every time). This isn’t intended to be the end-all-be-all of SDRs, but rather, as a starting point or an example for comparison. Any aspect of it might be boring/obvious to you, overkill, or just not useful, but my hope is that there is at least a part of it that will be helpful.
Because while I DO think I have some tricks that make my SDRs easier to use, I recognize that most of those tricks are things I only know or do because someone in the industry has shared their knowledge with me, or a client let me experiment a bit to find what worked best.
Because 33 Sticks doesn’t bill by the hour and I have no incentive to hoard “easy”/low-level tasks from my clients. If a client comes to me and says “I used your blog post to get started on an SDR without you”, I can say, “Great! That leaves us more time to get into more strategic work!”
Because where I can REALLY offer value as a consultant isn’t in the formatting/data entry part of creating an SDR, but rather, in the thought we put into designing/documenting solutions, and in how we help clients focus on goals and getting long-term value out of data so they don’t get stuck in “maintenance mode.”
And finally, because I’m hoping to hear back from folks and learn from them about what they’re doing the same or differently. We all benefit from opening up about our techniques.
Enough with the pedantry, let’s get back to discussing how to create a good SDR.
SDR Best Practices
It’s vitally important you keep your variable map in a centrally-accessible location. If I update a copy of the SDR on my hard drive, that doesn’t benefit anyone but me, and by the time I merge it back into the “global” one, we may already have conflicts.
It should go without saying, but keeping it updated is also a good idea. I actually view most types of Digital Analytics documentation as fitting into one of two categories: primarily useful at the beginning of an implementation, OR an ongoing, living document. Something like a Business Requirements Document COULD be a living document, but let’s be honest: its primary value is in designing the solution, and it can have a high level of effort to keep it comprehensively up-to-date. Technical specifications for the data layer are usually a one-time deal: after it is implemented, it goes into an archive somewhere. But the simple variable map… THAT absolutely should be kept current and frequently referenced.
Tools for Creation/Tracking
If you’re already using Adobe Analytics, then you probably need to get an accurate and current list of your variables and their settings. Even if you have an SDR, you should check if it matches what’s set up in your Analytics tool. You could always export your settings from within the Admin Console, but I’ve found the format makes the output very difficult to use. I’d recommend going with one of the many other great industry tools (all of which are free):
Adobe Consulting has a Health Dashboard that uses the Admin and Reporting APIs to not only pull down your settings, but show you the top values for each report and highlights recent changes in data.
If you use the Adobe Experience Cloud Debugger chrome extension and are logged in to the Experience Cloud, it will show you the friendly names of your variables directly in your beacon.
These tools are great for getting your existing settings, but they don’t leave a lot of room for planning and documenting the full implementation aspects of your solution, so usually I use these as a source to copy my existing settings into my SDR.
What should an SDR contain?
On our git repo, you’ll see an Excel sheet that has a generic example Variable Map. Even if you have an SDR that you like already, take a look this example one- there may be some items you might get use of (plus this post will be much more interesting if you can see the columns I’m talking about).
Pretty much ALL Variable Maps have the following columns (and mine is no different):
Variable/Report Name (eg, “Internal Search Terms”)
Variable/Report Number (eg, “eVar1”)
Description
Example Value
Variable Settings
But over the years I’ve found a few other columns can really make the variable map much more use-able and useful (and again, this all may make more sense if you download our SDR to have an example):
A “Sorting Order” or Key
If, like me, you love using tables, sorting, and filtering in Excel, you may discover that Excel doesn’t know how to sort eVars, props and events: because it isn’t fully a number or string, it thinks that the proper order is “eVar1, eVar10, eVar2, eVar20”. So if you’ve sorted for some small task and want to get back to a sensible order, you pretty much have to do things manually. For this reason, I have a simple column that has nothing other than numbers indicating my ideal/proper/default order for my table.
Param
This is for those who live their lives in analytics beacons rather than reports, like a QA team. It’s nice to know that s.campaign is the variable, and it is named “Tracking Code” in the reports, but it’s not exactly obvious that if you’re looking in a beacon, the value for s.campaign shows in the “v0” parameter.
Variable Type
Again, I love me some Excel filtering, and I like being able to say “show me just my eVars” or “show the out of the box events”. It can also be handy for those not used to Adobe lingo (“what the heck is an eVar?”). So I have a column with something like the following possible values:
eVar- custom conversion dimension
event- custom metric (eg “event1”)
event- predefined metric (eg “scAdd”, “purchase”)
listVar- custom conversion dimension list (eg, “s.list1”)
For things like this, where I have specific values I’ll be using repeatedly, I’ll keep an extra tab in the workbook titled “worksheet config”. Then I can use Excel’s “data validation” to pull a drop-down list from that tab.
Category
This is my personal favorite- I use it every day. It’s a way to sort/group variables and metrics that are related to each other- eg, if you are using eVar1, eVar2, prop1, event1, and event2 all in some way to track internal search, it’s nice to be able to filter by this column and get something like this:
The categories themselves are completely arbitrary and don’t need to map to anything outside of the document (though you might choose to use them in your Tech Spec or even in workspaces). Here’s a standard list I might use:
Content Identification
Internal Search
Products
Checkout
Visitor Segmentation
Traffic Sources
Authentication
Validation/Troubleshooting
Again, I could create/maintain this list in a single place on my “worksheet config” tab, then use “Data Validation” to turn it into a drop-down list in my Variable Map.
Status
This basically answers the question “is this variable currently expected to be working in production?” I usually have three possible values:
Implemented
Broken (or some euphemism for broken, like “needs work”)
In progress
Data Quality Notes
This is for, well, notes on Data Quality. Such as “didn’t track for month of March” or “has odd values coming from PDP”.
Last Validated
This is to keep track of how recently someone checked on the health of this variable/metric. The hope is this will help prevent variables sitting around, unused, with bad data, for months or even years. I even add conditional formatting so if it has been more than 90 days, it turns red.
Scope
Where would I expect to see this variable/metric? Is it set globally? Or maybe it happens on all cart adds?
Description
I’m certainly not unique in having this column, and I’m probably not unique in how many SDRs I’ve seen where this column has not been kept up-to-date. I’d like to stress the importance of this column, though- you may think the purpose of a variable is obvious, but almost every company I’ve worked with has at least one item on their variable map where no current member of the analytics team has any idea what the original goal was.
Ideally, the contents of this column would align with the “Description” setting within the Admin Console for each variable, so that folks viewing the reports can understand how to use the data.
We ARE all setting and using those descriptions, right? RIGHT?
Logic/Formatting and Example Value
Your Variable Map needs to have a place to detail the type of values you’d expect in this report. This:
helps folks looking at the document to understand what each variable does (especially if you don’t have stellar descriptions)
lets developers/implementers know what sort of data to send in
provides a place to make sure values are consistent. For instance, if I have a variable for “add to cart location”, there’s no inherent reason why the value “product details page” would be more correct than “product view”… but I still only want to see ONE of those values in my report. If folks can look in my variable map and see that “product details page” is the value already in use, they won’t go and invent a new value for the same thing).
I often find it a good exercise to run the Adobe Consulting Health Dashboard and grab the top few values from each variable to fill out this column.
Source Type
What method are we using to get the value for the data layer? I usually use Excel Data Validation to create this list:
query param
data layer
rule-based/trigger-based (like for most events, which are usually manually entered into a TMS rule based on certain conditions)
analytics library (aka, plugins)
duplicate of another variable
Dimension Source or Metric Trigger
This contains the details that complement the “source type” column: If it comes from query parameters, WHICH query parameter is it? If it comes from the data layer, what data layer object is it? If it’s a metric, what in the data layer determines when to fire it (for instance, a prodView event doesn’t map directly to a data layer object, but it does RELY on the data layer: we set it whenever the pageType data layer object is set to “product details page”.)
Variable Settings
This is something many SDRs have but can be a pain to keep consistent, because every variable type has different settings options:
As you can see, you’d have to account for a lot of possible settings and combinations- I’ve seen some SDRs with 30 columns dedicated just to variable settings. I tend to simplify and just have one column where I only call out any setting that differs from the default, such as “Expires after 2 weeks” or “merchandising: conversion syntax, binds on internal search event, product view, and cart add.”
Classifications
This should list any classifications set up on this variable. This is a good one to keep updated, though I find many folks don’t.
GDPR Considerations
Don’t forget about government privacy regulations! Use this to flag items that will need to be accounted for in your privacy policies and procedures. Sometimes merely having the column can serve as a good reminder that privacy is something we need to consider when designing our solution.
TMS Rule and TMS Element
I find these very helpful in designing a solution, but I’ll admit, they often fall by the wayside after an implementation is launched- and I don’t even see that as a bad thing. Once configured, your TMS implementation should speak for itself. (This will be even more true when Adobe releases enhanced search functionality in Launch.)
Other tabs
Aside from the variable map, I try to always have a tab/sheet for a Change Log. If nothing else, this can help with version control when someone had a local copy of the SDR that got off sync from the “official” one. It also lets you know who to contact if you have questions about a certain change that was made. I also use this to flag which changes have been accounted for in the Report suite Settings (eg, I may have set aside eVar2 for “internal search terms”, but did I actually turn it on in the tool?)
If you have many Report Suites, it may be helpful to have a tab that lists them all- their friendly name, their report suite ID, any relevant URLs/Domains, and perhaps the business owner of that Report Suite.
Also, if you have multiple report suites, you may want to add columns to the variable map or have a whole separate tab that compares variables across suites (the Report Suite exporter and the Observepoint SDR Builder both have this built in).
What works for you?
As I said, I don’t think my template is going to be the ultimate, universal SDR. I’d love to know what has worked for other people- did I miss anything? Is there anything I’m doing that I should do differently? Do you have a template you’d like to share? I’d love to hear from you!
UPDATE: The wonderful devs behind Adobe Launch have seen this and may be willing to build it in natively to the product. Please go upvote the idea in the Launch Forums!
As discussed previously on this blog, Direct Call Rules have gained some new abilities so you can send additional info with the _satellite.track method, but unfortunately, this can be difficult to troubleshoot. When you enabled _satellite.setDebug (which should really probably just be called “logging” since it isn’t exactly debugging) in DTM or Launch, your console will show you logs about which rules fire. For instance, if I run this JavaScript from our earlier blog post:
_satellite.track("add to cart",{name:"wug",price:"12.99",color:"red"})
I see this in my console:
Or, if I fire a DCR that doesn’t exist, it will tell me there is no match:
Unfortunately, this doesn’t tell me much about the parameters that were passed (especially if I haven’t yet set up a rule in Launch), and relies on having _satellite debugging turned on.
Improved Logging for Direct Call Rules
If you want to see what extra parameters are passed, try running this in your console before the DCR fires:
var satelliteTrackPlaceholder=_satellite.track //hold on to the original .track function
_satellite.track=function(name,details){ //rewrite it so you can make it extra special
if(details){
console.log("DCR NAME: '"+name+"' fired with the following additional params: ", details)
}else{
console.log("DCR NAME: '"+name+"' fired without any additional params")
}
//console.log("Data layer at this time:" + JSON.stringify(digitalData))
satelliteTrackPlaceholder(name,details) //fire the original .track functionality
}
Now, if I fire my “add to cart” DCR, I can see that additional info, and Launch is still able to run the Direct Call Rule:
You may notice this commented-out line:
//console.log("Data layer at this time:" + JSON.stringify(digitalData))
This is for if you want to see the contents of your data layer at the time the DCR fires- you can uncomment it if that’d also be helpful to you. I find “stringifying” a JavaScript object in console logs is a good way of seeing the content of that object at that point in time- otherwise, sometimes what you see in the console reflects changes to that object over time.
Improved Logging for “Custom Event”-Based Rules
If you’re using “Custom Event” rules in DTM or Launch, you may have had some of the same debugging/logging frustrations. Logs from _satellite.setDebug will tell you a rule fired, but not what extra details were attached, and it really only tells you anything if you already have a rule set up in Launch.
For example, let’s say I have a link on my site for adding to cart:
My developers have attached a custom event to this link:
var addToCartButton = document.getElementById("cartAddButton");
addToCartButton.addEventListener("click", fireMyEvent, false);
function fireMyEvent(e) {
e.preventDefault();
var myCustomEvent = new CustomEvent("cartAdd", { detail: { name:"wug", price:"12.99", color:"red" }, bubbles: true, cancelable: true });
e.currentTarget.dispatchEvent(myCustomEvent)
}
And I’ve set up a rule in Launch to listen to it:
With my rule and _satellite.setDebug in place, I see this in my console when I click that link:
But if this debugging doesn’t show up (for instance, if my rule doesn’t work for some reason), or if I don’t know what details the developers put on the custom event for me to work with, then I can put this script into my console:
var elem=document.getElementById("cartAddButton")
elem.addEventListener('cartAdd', function (e) {
console.log("'CUSTOM EVENT 'cartAdd' fired with these details:",e.detail)
}, false);
Note, you do need to know what element the custom event fires on (an element with the ID of “cartAddButton”), and the name of the event (“cartAdd” in this case)- you can’t be as generic as you can with the Direct Call Rules.
With that in place, it will show me this in my console:
Note, any rule set up in Launch for that custom event will still fire, but now I can also see those additional details, so I could now know I can reference the product color in my rule by referencing “event.detail.color” in my Launch rule:
Other tips
Either of these snippets will, of course, only last until the DOM changes (like if you navigate to a new page or refresh the page). You might consider adding them as code within Launch, particularly if you need them to fire on things that happen early in the page load, before you have a chance to put code into the console, but I’d say that should only be a temporary measure- I would not deploy that to a production library.
What other tricks do you use to troubleshoot Direct Call Rules and Custom Events?
As Page Performance (rightfully) gets more and more attention, I’ve been hearing more and more questions about the Performance Timing plugin from Adobe consulting. Adobe does have public documentation for this plugin, but I think it deserves a little more explanation, as well as some discussions of gotchas, and potential enhancements.
How It Works
Adobe’s Page Performance plugin is actually just piggybacking on built-in functionality: your browser already determined at what time your content starting loading and at what time is stopped loading. You can see this in a JavaScript Console by looking at performance.timing:
This shows a timestamp (in milliseconds since Jan 1, 1970, which the internet considers the beginning of time) for when the current page hit certain loading milestones.
Adobe’s plugin does look at that performance timing data, compares a bunch of the different milestone timestamps versus each other, then does some math to put it into nice, easy-to-read seconds. For instance, my total load time would be the number of seconds between navigationStart and loadEventEnd:
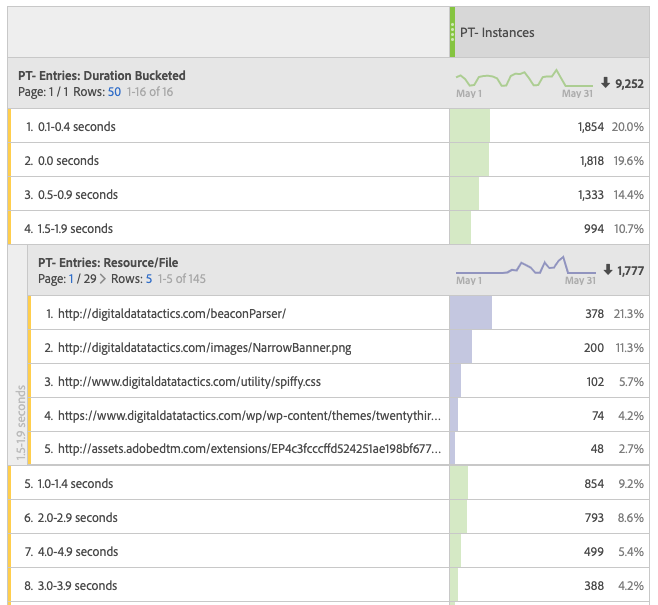
Additionally, if I choose to, I can have the plugin grab information from the built-into-the-browser performance.getEntries(), put it into session storage (not a cookie because it can be a long list), and put it into the variable of your choice (usually a listVar or list prop) on the next page. These entries show you for EACH FILE on the page, how long they took to load.
Unfortunately, if I’m sending my analytics page view beacon while the page is still loading, then the browser can’t tell me when “domComplete” happened…. because it hasn’t happened yet! So the plugin writes all these values to a cookie, then on your NEXT beacon, reads them back and puts them into numeric events that you define when you set the plugin up. This means you won’t get a value on the first page of the visit, and the values for the last page of the visit won’t ever be sent in. It also means you don’t want to break these metrics down by page, but rather by PREVIOUS page- so often this plugin is rolled out alongside the getPreviousValue plugin. This also means that the plugin is not going to return data for single-page visits or for the last page of visits (it may collect the data but doesn’t have a second beacon to send the data in on). for this reason, your Performance Timing Instances metric may look significantly different from your Page Views metric.
What It Captures
Out of the box, the plugin captures all of the following into events:
Redirect Timing (seconds from navigationStart to fetchStart- should be zero if there was no redirect)
App Cache Timing (seconds from fetchStart to domainLookupStart)
DNS Timing (seconds from domainLookupStart to domainLookupEnd)
TCP Timing (seconds from connectStart to connectEnd)
Request Timing (seconds from connectEnd to responseStart)
Response Timing (seconds from responseStart to responseEnd )
Processing Timing (seconds from domLoading to loadEventStart)
onLoad Timing (seconds from loadEventStart to loadEventEnd)
Total Page Load Time (seconds from navigationStart to loadEventEnd )
Instances (for calculated metric- otherwise you only really get the aggregated seconds, which is fairly meaningless if your traffic fluctuates)
Which gets you reporting that looks like this:
…Which, to be honest, isn’t that useful, because it shows the aggregated number of seconds. The fact that our product page took 1.3 million seconds in redirect timing in this reporting period means nothing without some context. That’s why that last metric, “instances”, exists: you can turn any of the first 9 metrics into a calculated metric that shows you the AVERAGE number of seconds in each phase of the page load:
This gives me a much more useful report, so I can start seeing which pages take the longest to load:
As you can see, the calculated metric can use either the “Time” format or the “Decimal” format, depending on your preference.
Performance Entries
As mentioned previously, the plugin can also capture your performance entries (that is, a list of ALL of the resources a page loaded, like images and JS files) and put them into a listVar or prop of your choice. This returns a list, delimited by “!”, where each value has a format that includes:
The name of the resource (ignoring query params)!at what second in the page load this resource started loading!how long it took for that resource to finish loading!resource type (img, script, etc).
For example, on my blog, I might see it return something like this:
From this, I can see every file that is used on my page and how long it took to load (and yes, it is telling me that the last resource to load was my analytics beacon, which started .7 seconds into my page loading, and took .2 seconds to complete). This is a LOT of information, and at bare minimum, it can make my analytics beacons very long (you can pretty much accept that most of your beacons are going to become POST requests rather than GET requests), but it can be useful to see if certain files are consistently slowing down your page load times.
An Enhancement: Time to Interaction
Unfortunately, the plugin most commonly used by folks omits one performance timing metric that many folks believe is the most critical: Time to DomInteractive. As this helpful site states:
Page Load Time is the time in which it takes to download the entire content of a web page and to stabilize.
Time to Interactive is the amount of time in which it takes for the content on your page to become functional and ready for the user to interact with once the content has stabilized.
In other words, Page Load Time might include the time it takes for a lot of background activity to go on, which may not necessarily stop the user from interacting with the site. If your page performance goal is for the best user experience, then Time To Interaction should be a key metric in measuring that. So, how do we track that? It already exists in that performance.timing object, so I tweaked the existing plugin code to include it. I can then create a calculated metric off of that (Time to Interactive/Page Performance Instances) and you can see it tells a very different story for this site than Total Page Load Time did:
9.49 seconds DOES sound like a pretty awful experience, but all three of these top pages had a much lower (and much more consistent) number of seconds before the user could start interacting with the page.
Basic Implementation
There are three parts to setting up the code for this plugin: before doPlugins (configuration), during doPlugins (execution), and after doPlugins (definition).
Configuration
First, before doPlugins, you need to configure your usage by setting s.pte and s.ptc:
s.pte = 'event1,event2,event3,event4,event5,event6,event7,event8,event9,event10,event11'
s.ptc = false; //this should always be set to false for when your library first loads
In my above example, here is what each event will set:
event1= Redirect Timing (seconds from navigationStart to fetchStart- should be zero if there was no redirect)- set as Numeric Event
event2= App Cache Timing (seconds from fetchStart to domainLookupStart)- set as Numeric Event
event3= DNS Timing (seconds from domainLookupStart to domainLookupEnd)- set as Numeric Event
event4= TCP Timing (seconds from connectStart to connectEnd)- set as Numeric Event
event5= Request Timing (seconds from connectEnd to responseStart)- set as Numeric Event
event6= Response Timing (seconds from responseStart to responseEnd )- set as Numeric Event
event7= Processing Timing (seconds from domLoading to loadEventStart)- set as Numeric Event
event8= onLoad Timing (seconds from loadEventStart to loadEventEnd)- set as Numeric Event
event9= Total Page Load Time (seconds from navigationStart to loadEventEnd )- set as Numeric Event
event10= Total Time to Interaction (seconds from connectStart to timeToInteraction)- set as Numeric Event. NOTE- THIS IS ONLY ON MY VERSION OF THE PLUGIN, OTHERWISE SKIP TO INSTANCES
event11= Instances – set as Counter Event
I’d also need to make sure those events are enabled in my Report Suite with the correct settings (everything should be a Numeric Event, with the exception of instances, which should be a Counter Event).
Execution
Within doPlugins, I need to just run the s.performanceTiming function. If I don’t want to capture performance entries (which is reasonable- not everyone has the listVars to spare, and it can return a VERY long value that can be difficult to get value out of), then I fire the function without any arguments:
s.performanceTiming()
If I DO want those performance entries, then I add the name of that variable as an argument:
s.performanceTiming("list3")
Also, you’re going to want to be capturing Previous Page Name into a prop or eVar if you aren’t already:
s.prop1=s.getPreviousValue(s.pageName,'gpv_pn');
(If you are already capturing Previous Page Name into a variable, you don’t need to capture it separately just for this plugin- you just need to be capturing it once somewhere).
Definition
Finally, where I have all of my plugin code, I need to add the plugin definitions. You can get Adobe’s version from their documentation, or if you want it with Time To Interactive, you can use my version:
/* Plugin: Performance Timing Tracking - 0.11 BETA - with JKunz's changes for Time To Interaction.
Can you guess which line I changed ;)?*/
s.performanceTiming=new Function("v",""
+"var s=this;if(v)s.ptv=v;if(typeof performance!='undefined'){if(perf"
+"ormance.timing.loadEventEnd==0){s.pi=setInterval(function(){s.perfo"
+"rmanceWrite()},250);}if(!s.ptc||s.linkType=='e'){s.performanceRead("
+");}else{s.rfe();s[s.ptv]='';}}");
s.performanceWrite=new Function("",""
+"var s=this;if(performance.timing.loadEventEnd>0)clearInterval(s.pi)"
+";try{if(s.c_r('s_ptc')==''&&performance.timing.loadEventEnd>0){try{"
+"var pt=performance.timing;var pta='';pta=s.performanceCheck(pt.fetc"
+"hStart,pt.navigationStart);pta+='^^'+s.performanceCheck(pt.domainLo"
+"okupStart,pt.fetchStart);pta+='^^'+s.performanceCheck(pt.domainLook"
+"upEnd,pt.domainLookupStart);pta+='^^'+s.performanceCheck(pt.connect"
+"End,pt.connectStart);pta+='^^'+s.performanceCheck(pt.responseStart,"
+"pt.connectEnd);pta+='^^'+s.performanceCheck(pt.responseEnd,pt.respo"
+"nseStart);pta+='^^'+s.performanceCheck(pt.loadEventStart,pt.domLoad"
+"ing);pta+='^^'+s.performanceCheck(pt.loadEventEnd,pt.loadEventStart"
+");pta+='^^'+s.performanceCheck(pt.loadEventEnd,pt.navigationStart);pta+='^^'+s.performanceCheck(pt.domInteractive, pt.connectStart);"
+"s.c_w('s_ptc',pta);if(sessionStorage&&navigator.cookieEnabled&&s.pt"
+"v!='undefined'){var pe=performance.getEntries();var tempPe='';for(v"
+"ar i=0;i<pe.length;i++){tempPe+='!';tempPe+=pe[i].name.indexOf('?')"
+">-1?pe[i].name.split('?')[0]:pe[i].name;tempPe+='|'+(Math.round(pe["
+"i].startTime)/1000).toFixed(1)+'|'+(Math.round(pe[i].duration)/1000"
+").toFixed(1)+'|'+pe[i].initiatorType;}sessionStorage.setItem('s_pec"
+"',tempPe);}}catch(err){return;}}}catch(err){return;}");
s.performanceCheck=new Function("a","b",""
+"if(a>=0&&b>=0){if((a-b)<60000&&((a-b)>=0)){return((a-b)/1000).toFix"
+"ed(2);}else{return 600;}}");
s.performanceRead=new Function("",""
+"var s=this;if(performance.timing.loadEventEnd>0)clearInterval(s.pi)"
+";var cv=s.c_r('s_ptc');if(s.pte){var ela=s.pte.split(',');}if(cv!='"
+"'){var cva=s.split(cv,'^^');if(cva[1]!=''){for(var x=0;x<(ela.lengt"
+"h-1);x++){s.events=s.apl(s.events,ela[x]+'='+cva[x],',',2);}}s.even"
+"ts=s.apl(s.events,ela[ela.length-1],',',2);}s.linkTrackEvents=s.apl"
+"(s.linkTrackEvents,s.pte,',',2);s.c_w('s_ptc','',0);if(sessionStora"
+"ge&&navigator.cookieEnabled&&s.ptv!='undefined'){s[s.ptv]=sessionSt"
+"orage.getItem('s_pec');sessionStorage.setItem('s_pec','',0);}else{s"
+"[s.ptv]='sessionStorage Unavailable';}s.ptc=true;");
/* Remove from Events 0.1 - Performance Specific,
removes all performance events from s.events once being tracked. */
s.rfe=new Function("",""
+"var s=this;var ea=s.split(s.events,',');var pta=s.split(s.pte,',');"
+"try{for(x in pta){s.events=s.rfl(s.events,pta[x]);s.contextData['ev"
+"ents']=s.events;}}catch(e){return;}");
/* Plugin Utility - RFL (remove from list) 1.0*/
s.rfl=new Function("l","v","d1","d2","ku",""
+"var s=this,R=new Array(),C='',d1=!d1?',':d1,d2=!d2?',':d2,ku=!ku?0:"
+"1;if(!l)return'';L=l.split(d1);for(i=0;i<L.length;i++){if(L[i].inde"
+"xOf(':')>-1){C=L[i].split(':');C[1]=C[0]+':'+C[1];L[i]=C[0];}if(L[i"
+"].indexOf('=')>-1){C=L[i].split('=');C[1]=C[0]+'='+C[1];L[i]=C[0];}"
+"if(L[i]!=v&&C)R.push(C[1]);else if(L[i]!=v)R.push(L[i]);else if(L[i"
+"]==v&&ku){ku=0;if(C)R.push(C[1]);else R.push(L[i]);}C='';}return s."
+"join(R,{delim:d2})");
You’ll also need to have s.apl and s.split.
You can see a full example of what your plugins code might look like, as well as a deobfuscated picking-apart of the plugin, on our gitHub.
Performance Entries Classifications
I recommend if you ARE capturing Performance Entries in a listVar, setting up 5 classifications on that listVar:
Resource/File
Starting Point
Duration
Duration- Bucketed (if desired)
Resource Type
Then set up a Classification Rule, using this regex string as the basis:
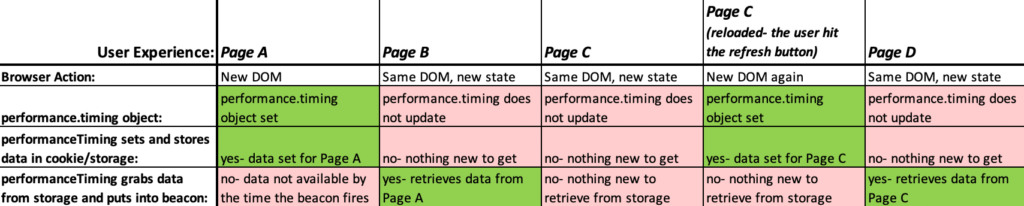
Unfortunately, this plugin will NOT be able to tell you how long a “virtual page” on a single page app (SPA) takes to load, because it relies on the performance.timing info, which is tied to a when an initial DOM loads. This isn’t to say you can’t deploy it on a Single Page App- you may still get some good data, but the data will be tied to when the overall app loads. Take this user journey for example, where the user navigates through Page C of a SPA, then refreshes the page:
As you can see, we’d only get performanceTiming entries twice- once on Page A and once on the refreshed Page C. Even without the “virtual pages”, it may still be worth tracking- especially since a SPA may have a lot of upfront loading on the initial DOM. But it’s not going to tell the full story about how much time the user is spending waiting for content to load.
You can still try to measure performance for state changes/”virtual pages” on a SPA, but you’ll need to work with your developers to figure out a good point to start measuring (is it when the user clicks on the link that takes them to the next page? Or when the URL change happens?) and at what point to stop measuring (is there a certain method or API call that brings in content? Do you having a “loading” icon you can piggy back on to listen to the end?). Make sure if you start going this route (which could be pretty resource intensive), you ask yourselves what you can DO with the data: if you find out that it takes an average 2.5 seconds to get from virtual page B to virtual page C, what would your next step be? Would developers be able to speed up that transition if the data showed them the current speed was problematic?
Use the Data
Finally, it’s important to make sure after you’ve implemented the plugin, you set aside some time to gather insights and make recommendations. I find that this plugin is one that is often used to just “check a box”- it’s nice to know you have it implemented in case anyone ever wants it, but once it is implemented, if often goes ignored. It is good to have in place sooner rather than later, because often, questions about page performance only come up after a change to the site, and you’ll want a solid baseline already in place. For instance, if you’re migrating from DTM to Launch, you might want to roll this plugin out in DTM well in advance of your migration so after the migration, you can see the effect the migration had on page performance. Consider setting a calendar event 2 weeks after any major site change to remind you to go and look at how it affected the user experience.
I’m honored to be included in the “Analytics Rock Stars 2019: Top Tips and Tricks” session at Adobe Summit this year in Vegas. I made my way onto the Rock Stars panel based on my entry for the inaugural Adobe Insider Tour stop in Atlanta, where I shared two tips:
Want to use Virtual Report Suites in place of Multi-suite tagging, but stuck on the need for different currency code settings? I’ve found a work-around that uses Incrementor Events so you can get local and report-suite-converted currency reports!
Copy and classify built-in Activity Map values to create automatic and friendly user navigation reports!
I don’t want to go into too much detail on this post- if you want more info, you’ll have to come to my session or ask me directly. Sign up for the session, then come introduce yourself!
Thus far in this series, we’ve discussed your options for a DTM-to-Launch Migration, and some potential areas you can improve upon your solution as part of a migration. As you can see from my previous posts, there are a lot of possible considerations for a DTM-to-Launch migration. So what might the actual process look like to get your company on Launch instead of DTM?
Figure Out How You’ll Roll Out
Does it make sense for your org to roll Launch out all at once to all of your properties? Or would you prefer to bite off one chunk at a time? (For instance, one client is currently updating their internal search single page app, so they’re going to roll out Launch there first, as a sort of guinea pig.) Keep in mind that even if you are only rolling out Launch to 3 pages first, ANY roll out is going to have to tackle some global logic- it may be that those first three pages are the hardest because you’ll need to tackle how to handle not just the requirements for those three pages, but also global items like authentication status or global marketing tags. If you do want to roll out all at once, you can keep using the same DTM embed code you always have so your developers don’t need to make changes to the pages, but that’s an all-or-nothing option (once you switch to Launch, Launch will “own” that embed code unless you choose to re-publish from DTM), and it only works in prod (dev/staging environments will still need the new embed codes).
Also, if you’re considering having DTM and Launch run alongside each other on the same page…. don’t even consider this an option. It won’t work. Both tools use the _satellite object and one WILL overwrite the other and/or get very confused by the presence of the other.
Validation
Keep in mind the effort to validate things- even if you are doing a “simple lift-and-shift”, you will still need to validate that Launch is doing all the things that DTM had been doing. Depending on how well-documented your current implementation is, and/or what QA efforts are currently in place, this may mean figuring out what it is that DTM is currently doing so you know whether Launch is matching it or not. This is a golden opportunity to set up some QA processes, if you haven’t already. If you don’t have a solid process already in place, you won’t be able to test every possible beacon for every possible user, but you should can set up a testing procedure in place for critical beacons on your most typical flows. Note, none of this is specific to DTM or Launch, but is a best practice regardless and will help with the DTM-to-Launch migration.
Establish key user flows and document each beacon in the flow’s expected variables
For your KPIs, in Adobe Analytics set up anomaly detection and/or alerts based on reasonable thresholds (alert me if revenue dips below $___ or visits climbs above ___)
This is all much easier if you used the migration as a chance to document your solution.
Audit What You’ve Got and What You Want
Unfortunately, Adobe does not provide a great way to document all of your current rules and data elements in DTM. Fortunately, there is a tool to help: Tagtician has a free chrome extension that can create a spreadsheet with a list of all your data elements, rules (including third party tags and what is deployed in the Adobe Analytics/Google Analytics section of each rule.) I cannot overstate how incredibly helpful this has been for every DTM migration project I’ve been on. Depending on how ambitious our migration plans are (on a scale of “lift-and-shift” to “burn it down and start fresh”), I’ve used this as a basis for a new solution design, so we know on each user action what variables are expected, where those variables are set, and where they pull their information from:
Then I take that to figure out how to deploy it through Launch (which may or may not look anything like how it was deployed in DTM): for instance, if pageName is always going to get it’s value from the same data element, I can set that in a global rule that fires on all page loads. Whereas my search variables can get their own rule, which will combine with the global rule on the search results page to create one analytics beacon with all the variables I need. Now that you can control load order and when analytics beacons fire in Launch, you may be able to really compartmentalize logic based on scope and get rid of redundancy in your implementation.
Decide On Your Publishing Flow
Launch has a new publishing flow- it’s no longer just staging vs production. You now have development (as many environments as you need), staging, and production; no changes automatically get built into a library unless you set it up to; you can use libraries to group together changes and move a group through the flow. If you only have one person in Launch at a time, and that one person tends to do most approvals and publishes, then the flow can definitely seem like “too much.” But for a lot of bigger organizations, this new flow is a game changer. Part of moving to Launch is figuring out how this flow should apply to your organization. For example, one client came up with something similar to this:
At the start of each sprint, they create a library with that sprint name, and link it to the main dev environment. Each member of their analytics team has their own permanent library in dev, linked to alternative dev environments (which aren’t referenced by any pages and are only really interacted with through the switcher plugin- basically a sandbox for them to build in, using the switcher plugin to see the effect of their efforts in dev). As changes are completed and pass their first round of validation, they get moved into the Sprint’s library, which at the end of the sprint moves into Staging, where it is validated by the developer/UX QA team before being approved and published. (This is just an example- there is no single “right way” to use this flow, it was designed to be flexible for a reason.) Be aware, once a library has “claimed” an environment (which is linked to an embed code), no other library can claim that environment, so if you want multiple libraries you will need multiple dev environments. Also, you can no longer use code in a developer console to switch between environments- currently, the only way I know to switch between environments is to use the Search Discovery switcher chrome extension or to use something like Charles Proxy Map Remote.
The Migration Project Plan
A DTM-to-Launch migration can become quite the involved project. For the simplest of migrations, it still may be 4-6 weeks to migrate within the tools, do any necessary validation, and publish your changes. It may only need to be one or two main analytics/TMS folks and/or a QA person working on it. Or, it may be a 9 month project that involves devs, QA/UAT, data architects, analysts… don’t underestimate the resource cost of the migration (though at the same time, don’t undervalue the long-term resource savings if you take the time to get it right as part of the migration and (re)build a scalable, maintainable, well-documented solution.) For instance, below is an example of how a Launch migration could go. This example does not include any changes to the data layer, but does include a substantial attempt to re-deploy analytics rather than merely shift the existing implementation with all the same rules and data elements.
Next Steps and Resources
As you can see, even a simple lift-and-switch to Launch can be a bit involved, and folks can feel daunted by all the considerations, options, and things to be aware of. I’ve tried to be as thorough and comprehensive as possible in this series, and I hope I hit the right level of detail to give practical guidance on how to tackle a DTM-to-Launch migration. There is a great community out there for folks who need DTM/Launch support- check out the following resources:
#measure Slack is a free Slack community full of practitioners, consultants, and Adobe product/community resources; I spend a lot of time in the #adobe-analytics and #adobe-launch channels
The Launch Developers Slack Forum is particularly helpful for those wanting to use the APIs, build extensions, or get technical best practices
And of course, the 33 Sticks blog, as well as my own blog, have lots of Launch content.
Hopefully this series helped, but feel free to reach out if you have questions or if you’d like to engage with us to make sure you get off on the right foot as you move to Launch.
Aside from all of the things that Launch handles better than DTM did (which I discussed a bit in my previous post in the series), a move to Launch provides an opportunity to clean up and optimize your implementation (to the point that even if you weren’t moving to Launch, you could still do this clean up within DTM). You can save yourself from headaches and regret down the line if you take the time now to define some standards, adopt some best practices, or apply some “lessons learned” from your DTM implementation.
Redo Your Property Structure
Many companies set up their DTM properties based on a certain understanding of how properties should be used, and realized a bit too late that a different set up might work better. A previous post of mine on this topic is still applicable in Launch: your properties should not be based on Report Suites or domains, but rather, on the three following questions:
How similar are the implementations between your sites (do they use the same data layer, for instance? Would the rules be triggered by the same conditions?)
How similar are the publication timelines (if you publish a change for Site A, would it also apply to Site B at that time?)
Will the DTM/Launch implementation be maintained/updated by the same folks? (Properties are a good way to control user access.)
Keep in mind Launch has an API for configuration, so if you have 15 properties and want to make a change to all of them at once, you now can (though that API is not yet super documented/supported, so it’s a bit of a wild west so far). In general, I’ve seen folks using Launch as an opportunity to move to fewer properties.
Define Standards and Best Practices
Now is a great time to take lessons learned from DTM and define the standards your company will follow within Launch. Some things are arbitrary- it doesn’t really matter if I name the rule “Product Details Page View” or “page: product details”, but if we are consistent from the start, it can save us a lot of head ache and cleanup down the road.
Tags With the Same Condition(s)/Scope Should Share the Same Rule
To keep your library light, and your implementation scalable and maintainable, I highly recommend basing your rules on their scope/condition, rather than the tags they contain. For instance, a single rule named “Checkout: Order Confirmation” is better than 10 different rules that fire on Order Confirmation- “Doubleclick Order Confirmation” and “Google Conversion Tags”, etc. I’ve written previously about why this matters– it can have a surprising affect on page performance (not to mention it cane make your TMS impossible to navigate/maintain), and that still applies in Launch.
Delete redundant and unused stuff
Run an audit of your DTM property. Do you have redundant or unused Data Elements? Empty (or permanently commented-out) rules or Third Party Tags? Inactive rules or data elements that aren’t likely to ever be used again? Often folks are afraid to delete things within DTM, but this is a great chance to delete anything that isn’t still useful.
Institute a Naming Schema
This is your chance to have a nice, clean naming standard in your TMS. Consider all the following things you can name in Launch:
Data Elements: I try to keep to the same [category]:[details], though since Launch doesn’t show the DE type from the DE list like DTM does, I also like to include the type: “search: term: QP” (QP for Query Parameter) or “checkout: order total:DL” (DL for Data Layer). I also prefer keeping everything for Data Elements lowercase so I don’t have to worry/remember how I capitalized things.
Rules: In DTM I liked to do something like “[category]:[scope/condition]” (eg “Search: Results”, “Catalog: Product Details”, “Checkout: Cart View”.) In Launch, because DCRs, EBRs and PLRs now share the same interface, I like to take it a step further and include the rule type at the front: “Page: Search: Results” or “Click: Search: Filter”. If you have a lot of rules potentially firing into the same beacon, then I’d also include info about the order (eg, “Page: Global: All Pages #100” and “Page: Home #25” so you know that the #100 one would fire AFTER the #25 one on the home page.) I’ve also found it helpful to call out the rules which actually fire my analytics BEACON as opposed to rules that run higher in the order and only set variables (eg: “Page: Global: All Pages (s.t) #100”). Then within Rules, there are more naming considerations than there had been in DTM:
Events: Should be descriptive, and it may be worth including the load order (so “Page Top- #100” or “Direct Call: Add to Cart #50” might do the trick.)
Conditions/Exceptions: Conditions and Exceptions particularly should have some sort of custom naming (instead of a condition “Core – Value Comparison”, I might name it “pageName DE=’search results’”).
Actions: I’ve been leaving some with the default (eg, “Adobe Analytics – Set Variables”, though depending on how complicated my implementation is, I might want to change that to “Analytics- Content Identification variables”). Any Core/Code actions should have a descriptive name (“Yahoo pixel- expires 12/19/19” or similar.)
Fix Up Your Data Layer
This is perhaps a very ambitious task for most migrations, but if you’re already taking the effort to audit your DTM implementation, now might be a good time to also look at your data layer- do you have data layer objects that aren’t being used in DTM at all currently? (Be aware, of course, that data layers don’t always exist solely for a TMS’s sake- make sure no one else is using it either). Before you go creating a bunch of data elements, is there something you wish your data layer had that it currently doesn’t? Or do you wish it were structured differently? Now might be a good chance to optimize it! Especially if you are rolling Launch out to one part of your site at a time, you may be able to work with devs to break up a Data Layer rollout into reasonable chunks. You may be surprised by how many devs are on board with fixing up the data layer, particularly if your current on is messy/confusing.
Move Third Party Tags to Asynchronous JS
This is one of the biggest areas for improvement I’ve seen amongst my current and past clients- they’ve potentially been using DTM for years and haven’t always taken advantage of DTM’s ability to improve page performance by moving third-party tags to asynchronous javascript.All tag managements systems have inherent weight- you are adding a JS library to your site. If you don’t mitigate this weight by using the TMS to optimize your tags, your TMS may be having a net-negative affect on your site- a substantial one, in many cases. I’ve written previously about the approach I would recommend for third-party tags, but to emphasize the importance of this: I have seen the overall page load time improve by 15-30% by simply moving tags within DTM to async. Unless the vendor’s code affects the user experience (chat, survey or optimization tools, for instance), there is no reason for most tags to be anything other than non-sequential JS.
In Launch, you can take it a step further, and use extensions to further optimize your tags. For instance, if you use Facebook or Doubleclick, there are extensions in place that you can use to move those tags entirely out of custom code blocks. Or, if you are deploying a simple pixel tag and the vendor does not have an extension, you can use 33 Sticks’ Pixel Loader extension to easily change it from an html tag to asynchronous javascript.
Document Everything!
Moving to Launch also provides the ability to get solid, current documentation on your solution. Aside from auditing your solution (I’ll take about that in a moment) so you know which rules are setting what or what is expected in the Data Layer on certain pages, I also recommend using this fresh start as a change to document and enforce your standards and best practices for TMS deployment. For instance, I’ve helped clients create a confluence document that anyone at thier company who might be within Launch can access, detailing:
Naming Strategy (see notes above)
Third Party Tag deployment standards (which tags are “approved” by your org for use- as in, “do not use one TMS to deploy another TMS like GTM, not unless you hate your site loading quickly”); deploying tags as asynchronous JS- see note above…)
I also recommend as part of the auditing/documentation process getting a list of all your third party tags, documenting who at your org “owns” that tag, and setting “expiration/renewal” dates (“Jan Smith owns this floodlight tag, deployed 8-5-18; on 9-5-18 we will contact her to see if the tag is still valid or can be deleted”).
Best Practices (don’t check “apply handler directly to element” without good reason, try to limit the number of Data Elements used in “Data Element Change” rule triggers, etc.)
Publication Flow (how is your org using libraries and environments? Who approves and who publishes? Will publishing happen with a specific cadence, like every other Wednesday? What is your QA/validation process? Do you want to implement an “all changes must be reviewed by someone other than the person who made the change” rule?)
I know this level of documentation can be daunting and seem like overkill, but your future staff/employees will thank you for it, even if it’s informal and/or a work-in-progress.
Change Your Deployment Method (Adobe-Managed vs Self-Hosted)
DTM had a few deployment options:
An Adobe/Akamai-hosted library (ie, your embed code starts with “//assets.adobedtm.com”)
An FTP self-hosted library (DTM would push changes through FTP to a location on your own servers)
A downloaded self-hosting option (you would manually download after changes and put onto your servers).
Now may be an opportunity to change this- if you’ve been doing the manual download option because of security concerns, now that the publishing flow in Launch is more flexible/powerful, might you be able to simplify by moving to another option?
Technically, all three of these options also exist in Launch, though the approach is slightly different. I’ve documented in a separate post how you can achieve each of the three methods in Launch- especially the download method, which may not be intuitive for users who had used the download option in DTM.
Update Your visitorID/appMeasurement Libraries
A TMS upgrade is also a good chance to update to the most recent stable Adobe libraries (for instance, as of this moment, the most current Analytics library is 2.10). Unless you are doing something very custom/weird in your libraries (or are stuck in the dark ages on H code), updating should be a relatively easy process, and offers benefits like improved page performance.
It may also make sense to examine your doPlugins function (if you are still using it): do you have functionality you can move out of doPlugins (eg, do you still really need getQueryParam when you can just use the DTM/Launch interface?) (Also, word on the street is that some folks at Adobe may be releasing an extension to handle many of the common plugins, so that may provide some extra room for enhancement.)
Update cross-Adobe Tool integrations
If you’re not yet on the VisitorID service, you really should be. Then once you are on that, now would be a good time to update your implementation for integrating analytics with other Adobe tools:
If you use Target, are you on at.js (and is it current)? Do you have Analytics 4 Target (A4T) set up?
If you use Audience Manager, have you transitioned to a server-side integration? Are you currently deploying your DIL at the bottom of your Analytics code in DTM, and might you be able to transition that to use the AAM extension?
What’s Next
By now, you should have a sense of what type of migration path you’re going to take, and what aspects of your solution you may want to change or improve upon. The next post in the series will walk you through the actual process and provide a rough framework for a project plan.
Adobe’s Launch is really building momentum (they just announced the plan to sunset DTM– editing abilities end December 31st, 2019 July 1st, 2020; read-only access dies June 2020 December 31st, 2020 (dates updated to reflect Adobe’s change)), and in the past few months, it feels like almost every day, I get asked “what does a launch migration look like?”
And I’m afraid I have a very unhelpful answer: it totally depends.
We’ve had visibility into about a dozen migrations now, and each one has been a completely unique case. But I figured I can at least defend my answer of “it depends” by clarifying what it depends on, what the options are, and what considerations should you make.
Disclaimer: Info in this series is accurate as of, October 29, 2018. We will try to update it as it makes sense to do so, but things can change quickly in the world of TMSes and iterative product releases.
You’ve Got Options
As far as we see it, if you’re considering a move from Adobe DTM to Launch, you have a few options:
Use the DTM-to-Launch Migration tool (SEE: Adobe’s documentation), essentially just doing a lift-and-shift of your current DTM implementation.
Use the DTM-to-Launch migration tool, but do a fair amount of clean up before/after.
Use a tool like Tagtician to audit what you currently have, decide what you want to carry over, and set it up “fresh” in Launch (have Launch accomplish the same thing as DTM, but perhaps accomplish it in different ways).
Use this as a chance to rebuild your solution from the ground up.
Most folks we’ve talked to or worked with are looking at somewhere in that 2-3 range. In most cases, we’d strongly discourage going with option #1, that straight-up lift-and-shift. I PROMISE there is some room for review and improvement in your DTM implementation.
First, not everything in DTM will work in Launch. Our friends at Search Discovery have a great tool for detecting places within DTM that you may be using code that will no longer work (goodbye, _satellite.getQueryParam). (NOTE: this detects places in your DTM library you are using those “forbidden” functions- if you are using something like _satellite.getQueryParam in your own javascript outside of DTM, it will not detect it.)
Technically, aside from the things that that tool will flag, everything that worked in DTM should work in Launch (actually, there are a few major differences you should be aware of). BUT, many of the workarounds you may have resorted to in DTM are no longer needed, so you can definitely optimize things. There are some broader differences between DTM and Launch that open the door for some changes to your implementation that could be really valuable.
Consider the following questions:
Are you currently using DTM for Single Page Apps? (if so, you’ve almost certainly had to use some workarounds that are no longer needed)
Do you have any repeated global logic (all of your DCRs or EBRs might be setting “eVar5=%auth status%” because you didn’t have a way to get that eVar included on all beacons otherwise)
Do you use Direct Call Rules heavily?
Do you have s.clearVars running in odd places?
Are a large portion of your Analytics variables being set in custom code blocks instead of in the interface?
Do you fire any Direct Call Rules from within your DTM implementation (eg, DCRs calling other DCRs to get around timing/scope issues?)
Are you currently firing Adobe Analytics beacons from outside of the Analytics Tool (eg, are you using a third party tag box to fire s.t or s.tl because of timing issues?)
If you answered yes to any of the above questions (and perhaps even if not), then you absolutely should be considering moving to Launch ASAP, for all the reasons discussed on these other blog posts:
Launch’s publication flow is much more flexible, making it easier to publish only what you want to publish to either Dev (as many environments as you want), Staging or Production
Even if you don’t have a Single Page App, or you are currently using any weird work-arounds to get DTM to work for you, you should use a migration as an opportunity to improve your implementation (which leads us to post 2 in the series: A Golden Opportunity).