Charles Proxy is a packet-sniffing tool often used by web analysts and developers to debug beacons being sent to Adobe. I find it has some advantages over other tools, even over the Adobe Debugger, because it isn’t looking at your javascript or your “s” object on your DOM, and isn’t tied to a specific browser window or page, but rather it looks at what traffic is actually being sent (and hopefully, successfully received) by Adobe, regardless of where or how it is sent.

This shows all the parameters (or variables) in your analytics beacon. Some very nice person put up a cheat sheet of how those parameters map to variables or are used in processing and reporting.
On top of looking at Analytics Beacons, I often use it to do the following:
- Examine which DTM files are loading, and in what order.
- Check that calls to other Adobe tools (Marketing Cloud ID Service, Target, Audience Manager) are happening in the right order, and with the right parameters.
- Route traffic from a mobile device through my desktop to see analytics beacons from that device (see instructions below).
- Use Tools>Map Local to use a file on my machine to replace one of my client’s pages in my browser (for instance, I could save the source of a client’s page, tweak it for my needs, save it to my desktop, and then use Charles Map Local to look at how that page would behave in place of the real one). This makes it easy to see how a client’s page acts when a DTM library is placed on it, or if certain code is removed.
- Use Tools>Map Remote to replace a file on the client’s site with a file from elsewhere on the internet. Often, this is to swap one DTM library out for another. Sometimes, I do this just to purposefully break a file- if I’m curious how a site would behave without jQuery, I might use map local to say “replace the jQuery file with a file at blank.js” (which doesn’t actually exist, so it effectively just says “don’t load the jQuery file). I did this often enough, and got sick of even seeing 404 errors, I created a blank file specifically for replacing other files.
- Get the full URL of a POST beacon, so I can use my beacon parser tool to split it out.
- Save a session of Analytics traffic so you can send it to peers.
- View the Headers and Cookies attached to a given beacon (at the bottom of a beacon, where you are viewing your params, switch from Query Params to either “Headers” or “Cookies”):

Charles is free if you’re ok with seeing a long splash screen and having sessions limited in length; it’s 50 dollars for a personal license if you want no splash screen and unlimited session length (I bought mine many years and many updates ago, it was worth every penny).
Charles Proxy and I have a bit of a love-hate relationship. It is pretty much ALWAYS open on my machine. It makes many aspects of my job so much easier. But sometimes, it just… doesn’t work. Many folks use the Tools>Rewrite capability to replace just certain code on the page, but it rarely works for me. And getting all the certification set up to accurately track SSL traffic is tricky. So, below is my guide for all the steps I follow when setting up Charles on a new machine to make it ideal for the type of tasks I test to do:
Install it
I prefer the Beta version since it happens to work better with my certificates and such, but for most folks the normal download should do just fine. After you install it, if you use Firefox, you’ll also want to download the Firefox extension- the easiest way is to go to Charles>Help>Install Mozilla Firefox Add-on. This is not needed for Chrome or the other common modern browsers.
Filter it
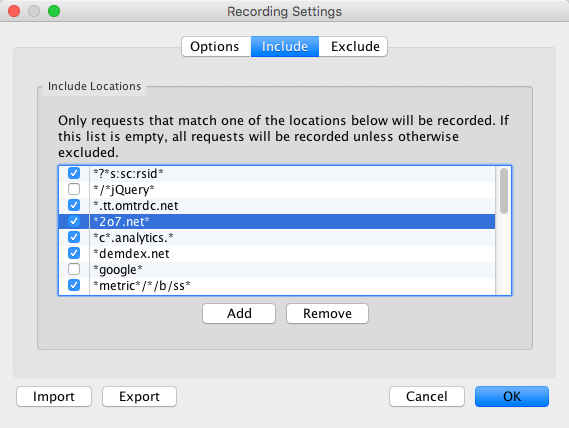
Charles captures ALL traffic sent from your machine to anywhere on the internet. It can be… comprehensive. I quickly find it to be too much information, and I use the “Include” tab in Proxy>Recording Settings to tell Charles to only show things relevant to my job. Below are the common ones (asterisks are wildcards):
- “assets.adobedtm.com” will show all Akamai-hosted DTM files. (If you self-host, you’ll want to add that URL up to the folder that contains your scripts- in other words, stop just before it says “/satelliteLib-“. That way you see ALL DTM files, like your s_code file, not just your main library)
- “*demdex.net” shows Audience Manager and Marketing Cloud ID calls (fun fact: the Marketing Cloud ID service uses technology gained from Adobe’s acquisition of Demdex).
- “*.tt.omtrdc.net” shows Target calls
- Whatever domain you capture your analytics tracking on. For instance, on this site, my non-secure beacons are sent to “jenniferkunz.d1.sc.omtrdc.net”. Make sure you include both the secure and non-secure domains. If in doubt, you may be able to check this by seeing what your s.trackingServer and s.trackingServerSecure variables are set to in your s_code.
- Because I have many Analytics clients, I also include all the common domains for analytics tracking, but you may not want to do this because you’ll catch many beacons not relevant to your implementation:
- “*.2o7.net” for non-RDC, non-CNAME implementations
- “*.omtrdc.net” for RDC implementations
- “*metric*” as the domain and “*/b/ss*” as the path, to capture a vast majority of CNAME implementations.
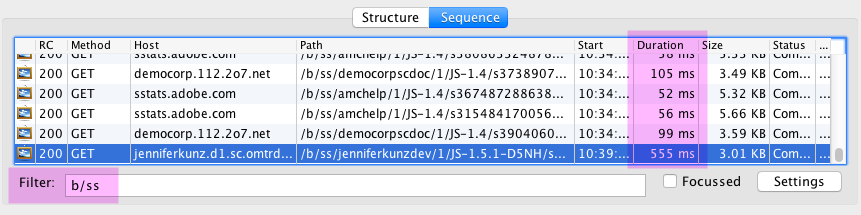
Use “Sequence” Mode
Most folks use “Structure” mode for viewing beacons, where a panel on the left will show all traffic, broken down by domain:
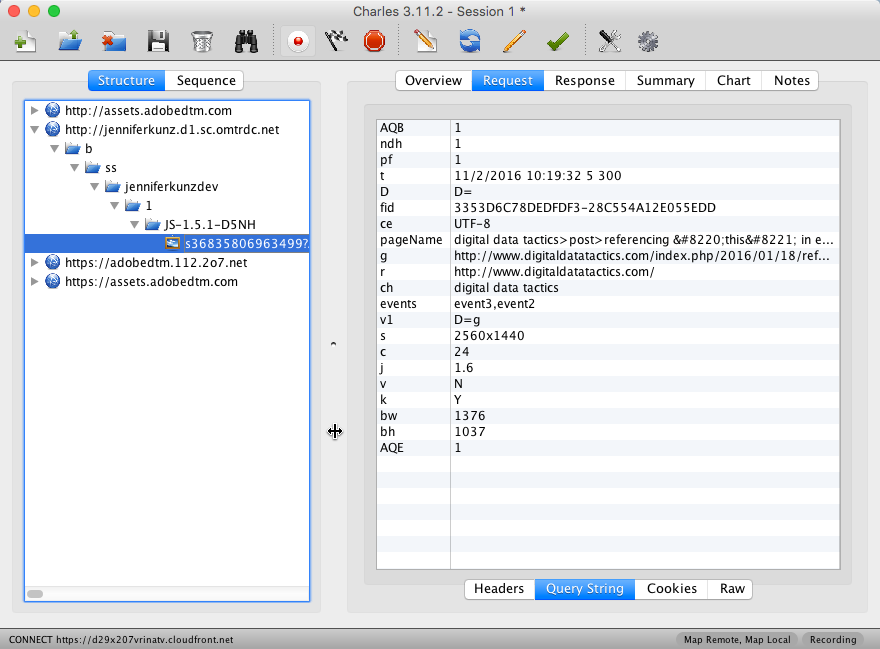
I used this for years before realizing how much more I like sequence mode, which offers a few benefits:
- It shows things in the order that they occur (making it easy to spot things like “uh-oh, the marketing cloud ID service hadn’t responded by the time my beacon fired”
- You don’t have to know the root domain of your beacons off the top of your head. Secure and non-secure beacons are shown alongside each other.
- It makes it very easy to filter. I often filter by “b/ss” to show only Analytics beacons, but you could also filter by “v0” to see only beacons that set the s.campaign variable, or by “landing” to show only beacons that had a pageName including “landing”.
Get it working with SSL
By default, Charles can’t read traffic from secure sources- or it can only show them with encrypted values (generally useless for debugging). There is information on the Charles site about setting up SSL tracking, but it can be hard to know what it means for you.
First, you need to set up a Root Certificate on your machine, giving Charles control over how your machine handles SSL Certificates. Go to Help>SSL Proxying>Install Charles Root Certificate. Follow the prompts from your operating system, but keep a careful eye out for two settings:
- From the Charles site (specific to windows): “The certificate must be imported into the “Trusted Root Certification Authorities” certificate store, so override the automatic certificate store selection.”
- Ensure the certificate is set to “Always trust” (if you miss this setting first time around, and you’re on a mac, you can change it later by opening your keychain.
If you have Firefox, you’ll also need to install the certificate through Firefox. If you’ve installed the Charles extension, then within Firefox you should be able to go to Tools>Charles Proxy>Install Charles Root Certificate. When given the option, click “Trust this CA to identify websites”.
All of this has gotten Charles primed to listen for SSL traffic, but you still need to tell Charles which specific sites it can listen to, by going to Proxy>SSL Proxying Settings>SSL Proxying and entering the domains of your SSL analytics traffic. I tend to have this list pretty closely match by list of overall traffic filters, mentioned above (eg: “*2o7.net”, “*omtrdc.net”, “assets.adobedtm.com”, and “smetrics.*.com”). (Update 2023: adobedc.net or “/ee/” seem like good filters for Adobe Experience Platform traffic).
Use it for Mobile Devices
If you want to route your traffic from a mobile device through Charles, it’s fairly simple. Below are instructions for an iOS device… sorry Android users, you’ll need to google to find similar instructions). Your mobile device and your desktop will need to be on the same network (ie, same WiFi). If your desktop is on VPN, your phone will need to be too.
First, if you will be looking at secure traffic, you’ll need to install the Charles certificate to your device. On your device, go to http://www.charlesproxy.com/getssl and follow the prompt. Pretty easy.
Next, get your local IP address (hint: this is different from your overall IP address, and specific to within your network). Charles makes this easy- in Charles, go to Help>Local IP Address. You may want to jot this down and close this window, because when you get things working, Charles will want to pop up another window you need to pay attention to.
Lastly, on your phone, open up your WiFi settings and scroll to the bottom. Under HTTP Proxy, select “Manual”, then under Server, enter the Local IP address you noted above. Under Port, enter “8888”. Then click Renew Lease. (2023 update- I don’t believe Renew Lease is needed anymore, or even an option).

[update- September 2017): If you still have issues with SSL traffic and get a “SSLHandshake: Received fatal alert: unknown_ca” error, you may need to go into your device’s settings- Settings > General > About > Certificate Trust Testings – and make sure the Charles Proxy Custom Root Certificate is marked as trusted.
Don’t forget to switch this back to “off” when done.
Now move out to your browser and do a simple test to see if traffic gets sent and shows in Charles. The first bit of traffic should prompt a Charles warning on your machine, asking you to Allow this traffic. If you miss this setting the first time around, you can tweak it under Charles>Tools>Access Control Settings.
Troubleshooting
If after all of this, it isn’t working right, here’s a few things to try:
- If you are on VPN, and Charles isn’t cooperating, try switching the order you do things in: perhaps by opening your VPN first, THEN Charles, or the other way around. Experiment.
- If Charles works in one browser and not in another, check your Proxy menu: are you set to capture traffic data both on your OS (and therefore Chrome), as well as Firefox?
- If Charles is interfering with things like your email server, check out your Bypass Proxy settings.