
What’s a Data Layer?
Tag Management Systems can get data a variety of ways. For instance in DTM you can use query string parameters, meta tags, or cookie values- but in general, data for most variables comes from one of two sources:
- To really take advantage of a tag management system like DTM, I may choose to scrape the DOM. I’m gonna call this the MacGyver approach. This uses the existing HTML and styles on a site to For instance, DTM could use CSS selectors to pull the values out of a <div> with the class of “breadcrumb”, and end up with a value like “electronics>televisions>wide-screen”. This relies on my site having a reliable CSS structure, and there being elements on the page that include the values we need for reporting.
- If I want even more flexibility, control and predictability, I may work with developers to create a data layer. They would create a JavaScript object, such as “universal_variable.pageName”, and give it a value based on our reporting needs, like “electronics | televisions | wide-screen > product list”. This gives greater control and flexibility for reporting, but requires developers to create JavaScript objects on the pages.
Conceptually speaking, a data layer is page-specific (but tool-agnostic) metadata that describes the page and the actions a user may take on it. Practically speaking, a data layer typically consists of a JavaScript object that contains all of the values we’d want to report on for a given page or user.
Data layers are important because they save developers time by allowing them to abstract out the metadata into a tool-agnostic syntax that a TMS like DTM can then ingest and set as data elements. Whereas once I would have told IT “please set s.prop5 and s.eVar5 to the search term on a search results page, and set s.events to event20” now I can just say “please put the search term in a javascript object such as digitalData.page.onsiteSearchTerm and tell me what object it is.” Then the TMS administrators could easily map that to the right variables from there.
You can see an example data layer if you’d like, or you can pull open a developer console for this very blog and look at the object “digitalDataDDT” to see the data layer that is automatically created from Search Discovery’s wordpress plugin.
Why a Data Layer?
My friends at 33 Sticks also have a great blog post on the subject, but I’ll list out some of the reasons I prefer clients to use a Data Layer. To me, it’s an upfront investment for a scalable, easily maintained implementation going forward. It does mean more work upfront- you have to first design the data layer to make sure it covers your reporting requirements, then you’ll need developers to add that to your site. But beyond those upfront tasks, configuration in your TMS will be much simpler, and it will save you many hours of CSS guess work and DOM scraping, and it may prevent broken reporting down the line.
| Upfront LOE | Maintenance LOE | ||||
| Route | Amount of Control | Dev | Analytics | Dev | Analytics |
| Old fashioned “page on code” | Medium | Heavy | Heavy | Heavy | Heavy |
| DTM + “Macgyver” | Low | Minimal | Heavy | Minimal | Heavy |
| DTM + Data Layer | High | Heavy | Medium | Minimal | Minimal |
Another potential benefit to a Data Layer is that more and more supplementary tools know how to use them now. For instance, Observepoint’s site scanning tool can now return data on not just your Analytics and Marketing beacons, but on your Data Layer as well. And one of my favorite debugging tools, Dataslayer, can return both your beacons and your data layer to your console, so if something is breaking down, you can tell if it’s a data layer issue or a TMS issue.
Ask Yourself
Below are some questions to ask yourself when considering using a data layer:
How often does the code on the site change? If the DOM/HTML of the site changes frequently, you don’t want to rely on CSS selectors. I’ve had many clients have reports randomly break, and after much debugging we realized the problem was the developers changed the code without knowing it would affect analytics. It’s easier to tell developers to put a data layer object on a page then leave it alone, than it is to tell them to not change their HTML/CSS.
How CSS-savvy is your TMS team? If you have someone on your team who is comfortable navigating a DOM using CSS, then you may be able to get away without a data layer a little more easily… but plan on that CSS-savvy resource spending a lot of time in your TMS. I’ll admit, I enjoy DOM-scraping, and have spent a LOT of time doing it. But I recognize that while it seems like a simple short-term fix, it rarely simplifies things in the long run.
How many pages/page types are on the site? A very complicated site is hard to manage through CSS- you have to familiarize yourself with the DOM of every page type.
How are CSS styles laid out? Are they clean, systematic, and fairly permanent? Clearly, the cleaner the DOM, the easier it is to scrape it.
How often are new pages or new site functionality released? Sites that role out new microsites or site functionality frequently would need a CSS-savvy person setting up their DTM for every change. Alternatively, relying on a data layer requires a data-layer-savvy developer on any new pages/site/functionality. It is often easier to write a solid Data Layer tech spec for developers to reference for projects going forward than to figure out CSS selectors for every new site/page/functionality.
How much link-tracking/post-page-load tracking do you have on your site? If you do need to track a lot of user actions beyond just page loads, involving IT to make sure you are tracking the right things (instead of trying to scrape things out of the HTML) can be extremely valuable. See my post on ways to get around relying on CSS for event-based rules for more info on options.
What is the turn-around time for the developers? Many clients move to DTM specifically because they can’t work easily within their dev team to set up analytics. A development-driven data layer may take many months to set up, stage, QA, and publish. Then if changes are needed, the process starts again. It may be worth going through the lengthy process initially, but if changes are frequently needed in this implementation, you may find yourself relying more on the DOM.
Are there other analytics/marketing tag vendors that may use a data layer? You may be able to hit two birds with one stone by creating a data layer that multiple tools can use.
Have you previously used another tag management system? Often, a data layer set up for a different tool can be used by DTM. Similarly, if the client ever moves away from DTM, their data layer can travel with them.
Does the site have jQuery? The jQuery library has many methods that help with CSS selectors (such as .parent, .child, .closest, .is, .closest…). A CSS-selector-based implementation may be more difficult without jQuery or a similar javascript library.
Who should create my Data Layer?
Ideally, your data layer should be created by your IT/developers… or at bare minimum, developers should be heavily involved. They may be able to hook into existing data in your CMS (for instance, if you use Adobe Experience Manager you can use the Context Hub as the basis for your data layer), or they may already have ideas for how they want to deploy. Your data layer should not be specific to just your Analytics solution; it should be seen as the basis of all things having to do with “data” on your site.
Yet frequently, for lack of IT investment, the analytics team will end up defining the data layer and dictating it to IT. These days, that’s what most Tech Specs consist of: instructions to developers on how to build a data layer. Usually, external documentation on data layers (like from consulting agencies) will be based on the W3C standard.
The W3C (with a task force including folks from Adobe, Ensighten, Microsoft, IBM…) has introduced a tool-agnostic data layer standard that can be used by many tools and vendors. The specifications for this can be found on the W3C site, and many resources exist already with examples. Adobe Consulting often proposes using the W3C as a starting point, if you don’t have any other plans. However, in my experience, generally that W3C is just a starting point. Some people don’t like the way the W3C is designed and most everyone needs to add on to it. For example, folks might ask:
- why is “onsiteSearchTerms” part of digitalData.page? Can I put it instead in something I made up, like digitalData.search?
- I want to track “planType”- the W3C didn’t plan for that, so can I just put it somewhere logical like digitalData.transaction?
- I don’t need “digitalData.product” to be in an array- can I just make that a simple object.
The answer is: yes. You can tweak that standard to your heart’s delight. Just please, PLEASE, document it, and be aware that some tools will be built with the official standard in mind.
The Phased Approach
Many folks adopt a TMS specifically because they don’t want to have to go through IT release cycles to make changes to their implementation. You can still use a TMS to get a lot of what you need for reporting without a data layer and without a ton of CSS work. It may be worthwhile to put a “bare minimum” TMS deployment on your site to start getting the out of the box reports and any reports that don’t require a data layer (like something based on a plugin such as getTimeParting), then to fill in the data layer as you are able. I’d be wary though, because sometimes once that “bare minimum” reporting is in place, it can be easy to be complacent and lose some of the urgency behind getting a thorough solution implemented correctly from the start.
Conclusion
I fully understand that a properly designed data layer is a lot of work, but in my experience, there is going to be a lot of effort with or without a data layer- you can choose for that effort to be upfront in the planning and initial implementation, or you can plan on more longterm maintenance.
One of the goals of a data layer (more so when working in tandem with a tag manager) is to provide a standardized and centrally managed source of data that any/all analytics packages on your site can pull from.
Isn’t another goal of a DDL (at least the W3C’s CEDDL) to create an industry standard for how that data is accessed regardless of the site? For example, the page name is always stored in digitalData.page.pageInfo.pageName. Of course every site is a bit different, but my specific concern with the W3C DDL is the seemingly conflicting ways to extend the spec.
The docs say you can add an ‘attributes’ property containing custom properties (which can use any name, i.e. even “reserved names” you want) OR add custom first-level OR sub-level objects inside properties already specified by the CEDDL.
So, except for the ability to use reserved names in the ‘attributes’ property, why would one method be used over another?
More thoughts:
Pretty much all the articles I’ve read really only mention using the ‘attributes’ property to extend the spec, and one of the spec’s own example (section 7.1 “Example from Air Travel Industry”of the PDF) *doesn’t* use the ‘attributes’ property. **What are the spec’s authors’ thoughts on which one of those two options are best for various situations?**
On one hand, avoiding the ‘attributes’ property to reduce the depth of the nested objects (Tealiums’s DDL is flat) and to keep the DDL as simple as possible would be good goals. On the other hand, a new analytics employee working on a site may have a hard(er) time finding some data because it’s mixed in with the other already-spec’d properties, etc instead of in the attributes property.
Any thoughts on this?
Also, Appendix A (Reserved Names and Identifiers) says “Avoid the following Reserved Words, Predefined Names, and Event Handlers for the object or property names when extending the specification.”
There are a good amount of useful names in the Appendix. It says not to use “digitalData.transaction.status”, yet that would be a perfect name for the, well, status of a transaction (like, “Validating”, “Charging”, “Disputing”, “Refunded”, etc). Does Appendix A also apply to the ‘attributes’ property?
I tend to skip using “attributes” and just adding in custom objects where they fit. But to your point, that may be hard for someone new to the solution. The only answer is good documentation:).
Hey Jenn,
Love the site. I could have swore on one of your posts or pages I saw an image or a link to an example SDR.. I can’t find it anymore and it had basically also shown the pages (I think) and was more like a guide for developers to know where the code needs to be implemented or lives – page template level or url I can’t remember. But it was neat and I could have swore it came from your blog this last week but I can’t find it now. If you can remember on the fly and let me know, would be greatly appreciated!
Hm, I don’t know if I ever posted one online anywhere, and it can be tricky getting one that isn’t proprietary (either client-specific, or consultancy-specific), but I do certainly have a lot of those floating around.
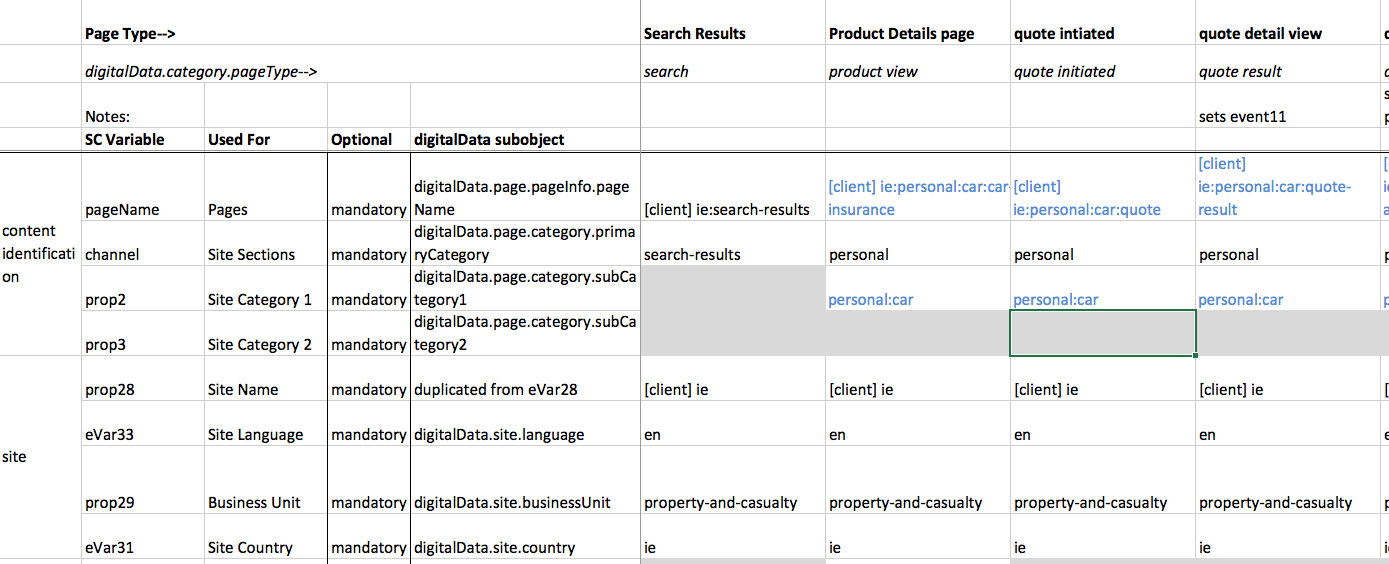

Both observepoint (https://help.observepoint.com/customer/en/portal/articles/2584149-sdr-builder-overview) and adobe (https://files.acrobat.com/a/preview/22c2b284-af2d-4f4b-9026-9e02404729c4) have decent tools for generating an SDR, but both of those are much more about getting your variable settings and such. As for documenting for developers, there’s a few formats I like.
One is a spreadsheet that has rows for each variable, and columns for each user action/page type being tracked (or the same idea, but switch rows/columns). Something like this (not my prettiest example, but the only one I have that isn’t client-specific):
For a more top-down view, I often just add columns to the standard SDR for DTM type (seen here as “implementation scope), Data Element name, Data Source, and DTM rule- but I find that getting a thorough list of the rules and relationships between things is really hard to do without having done my previous spreadsheet walking through each page type/user action to be tracked.
Lastly, I might make a word document tech spec that has a “for this user action, set this data layer stuff, which should generate this beacon” but I find that often isn’t needed if you have it in spreadsheet form with a bit of instruction.
Hope this helps!
This is a great article. Kudos!!